The Lab
Experiments in quantifying the uninsurable.
I am currently building AION, an AI-native underwriting engine designed to bridge the gap between technical space data and insurance capital.
This feed documents the build in real-time: the technical bottlenecks, the architectural pivots, and the solutions required to deploy a working Risk Engine.
Active Module: M2 (Context & Explainability)
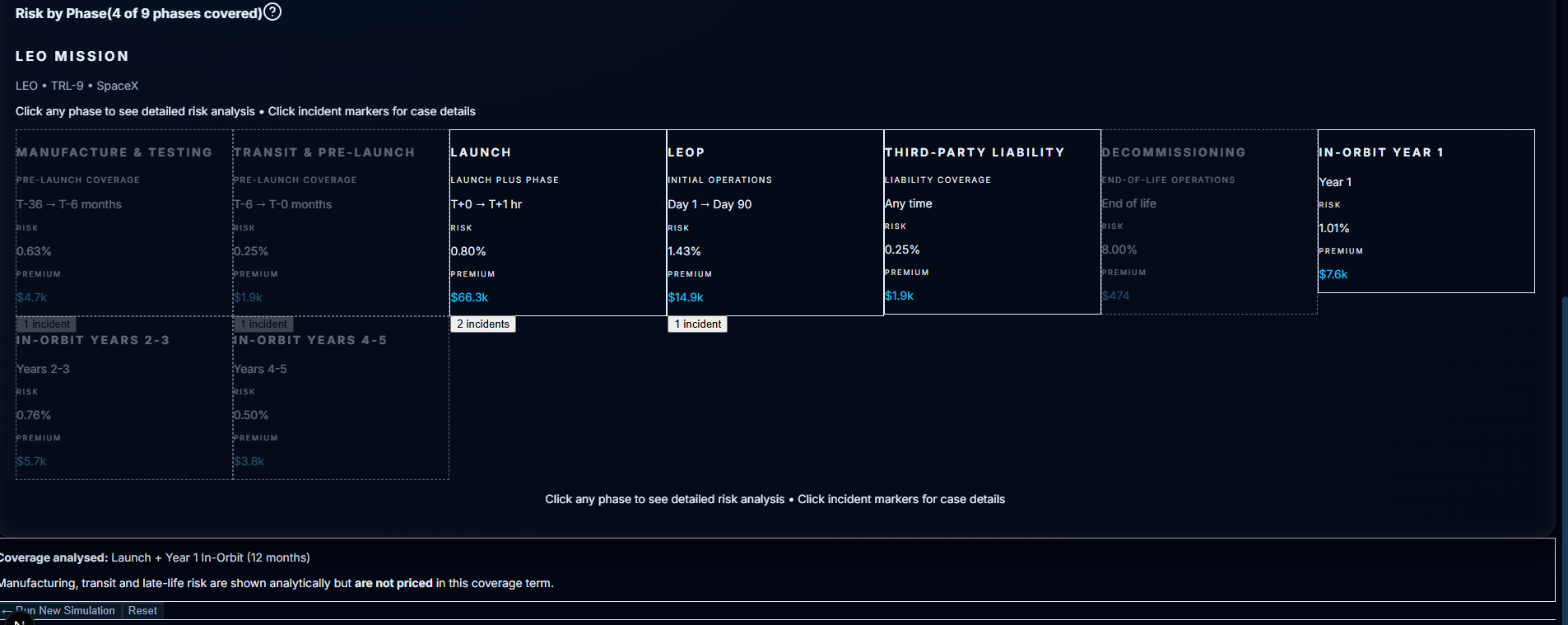
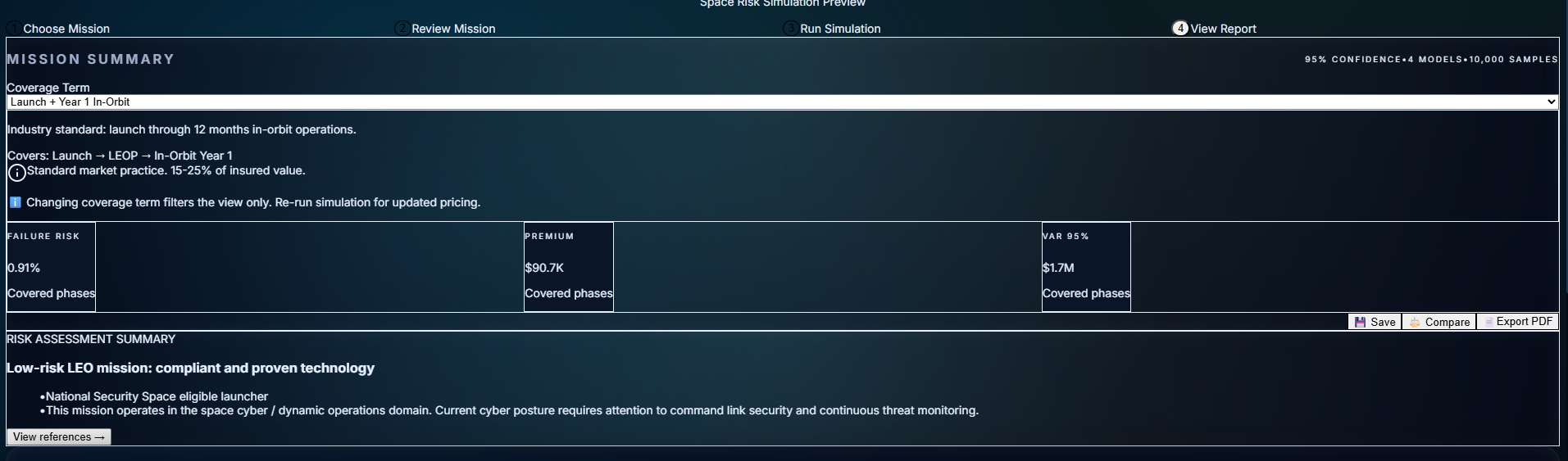
AION: Module 2 — From Black Box to Glass Box
The Problem: Calculators Aren't Enough
Module 1 gave you numbers. You could configure a mission, run the Monte Carlo model, and get a premium out the other side. It was fast. It was mathematically sound.
But in speciality insurance, numbers aren't enough.
A junior underwriter can run a model. A senior underwriter knows the model is only 10% of the story. They ask:
"Is this mission even legal under current UKSA regulations?"
"Have we seen a similar satellite configuration fail in LEO before?"
"Is this operator sanctioned?"
"Why is the premium 12.4%?"
If your system can't answer those questions—if it just says "trust me"—it's useless in the Lloyd's market. You need to defend every quote to capital providers, brokers, and regulators.
Module 1 turned AION into a risk brain.
Module 2 is the difference between a calculator and a senior underwriter.
It's the Context Engine: the piece that checks regulatory compliance, remembers past missions, explains every metric, and cites its sources. It turns AION from "here's a number" into "here's a defensible underwriting decision with regulatory backing and portfolio precedent."
Timeline: December 2–11, 2025 (9 days, ~180 hours) · Status: ✅ Frozen for V1

What I Built: The Context Engine
Module 2 delivers four core capabilities:
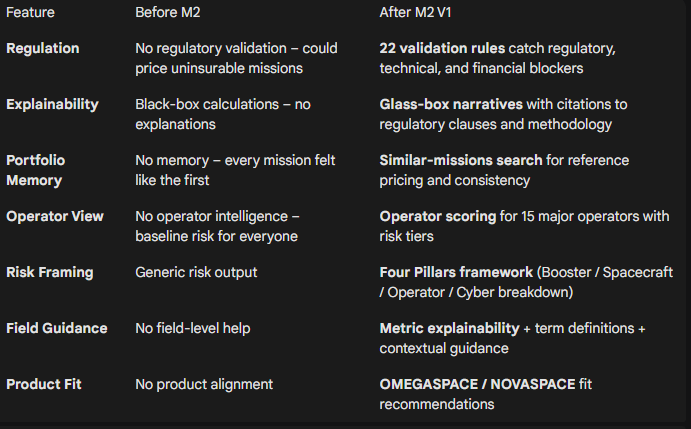
1. Regulatory Validation (22 Rules)
A rule engine that checks missions against international regulations, market access restrictions, technical safety requirements, and financial viability before pricing runs.
Traffic-light system (GREEN / AMBER / RED)
Each flag backed by citations to specific regulatory clauses
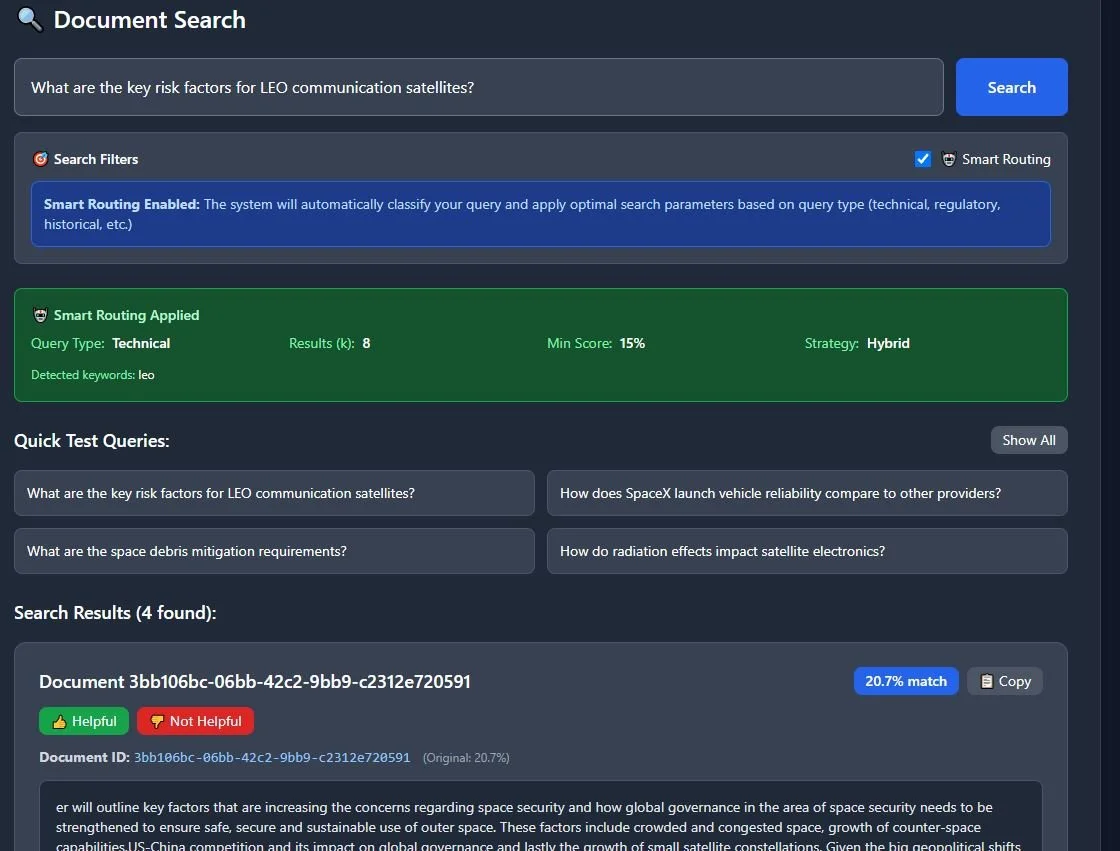
2. Hybrid Search + Glass-Box Narrative
A search engine that fuses:
vector similarity (semantic meaning)
BM25 keyword search
recency
reliability scoring
Every risk assessment comes with a narrative: bullet points, regulatory citations, and methodology references.
Not just "premium is 5.6%" but "here's why, here's the clause, here's the comparable mission".
3. Portfolio Memory (Similar Missions)
Every priced mission is saved as an embedding.
When a new submission comes in, the system finds similar missions by orbit, mass, heritage, and premium band.
"We've seen this before" → instant reference pricing and consistency.
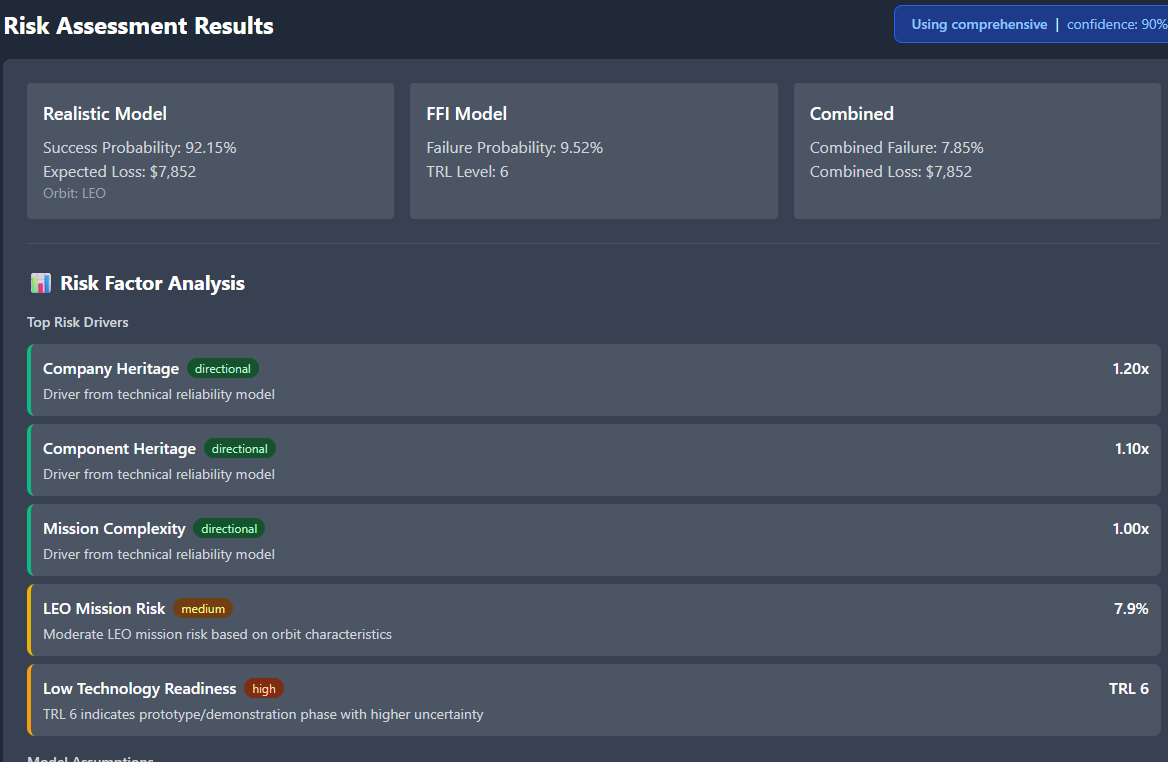
4. Metric Explainability
Click any metric (failure_risk, premium, VaR, phase risks) and get:
the formula used
the inputs for this mission
comparable values from similar missions
links back to methodology docs
It takes AION from black box to glass box.
Before Module 2 vs After Module 2
Module 2 is now FROZEN for V1.
This isn't ongoing tinkering—it's a shipped, production-ready module with 30 passing tests, 80%+ coverage, and complete documentation.
Next step: build on top of it with Module 3.
How It Works: Inside the Context Engine
Building a glass box isn't just prompt engineering. It requires architecture that forces the AI to check its facts before it speaks.
3a. Regulatory Validation: The Gatekeeper
Module 2's rule engine runs before any pricing logic. It applies 22 validation rules across four categories:
Regulatory compliance: ISO 24113 (25-year disposal), FCC 5-year deorbit, UKSA licensing
Market access: ITAR/EAR restrictions (China, India, Vietnam, Thailand)
Financial viability: Flags operators with <6 months funding runway
Sanctions & export control: LMA 3100A sanctions clause, US content thresholds
Each mission gets a traffic light (GREEN/AMBER/RED). RED flags block the quote entirely. AMBER flags add premium loadings with regulatory justification.
Example: A LEO constellation with a Chinese parent company triggers the Foreign Ownership Rule → AMBER flag → cites specific ITAR clause → adds 15% premium load.
This isn't an LLM guessing. It's deterministic logic checking real regulatory requirements. It stops you from wasting capital on uninsurable risk.
3b. Hybrid Search + Glass-Box Narrative
The biggest risk in AI for insurance isn't hallucination—it's opacity.
To solve this, I built a hybrid search engine that fuses:
Vector search (pgvector HNSW) for semantic similarity
BM25 keyword search (PostgreSQL full-text) for exact clause matches
Reciprocal Rank Fusion to merge results
Weighted scoring: 40% semantic + 30% keyword + 15% recency + 15% reliability
The corpus includes UKSA regulations, ISO standards, FCC rules, ESA guidelines, and internal methodology docs (Weibull parameters, pricing logic, Monte Carlo VaR).
Every risk narrative comes with citations. Not "this mission is risky because AI said so" but "this mission triggers Clause 5.1 of ISO 24113 because the deorbit plan exceeds 25 years."
The system doesn't just find close text—it finds the most trustworthy clauses for the specific mission configuration.
3c. Portfolio Memory: "We've Seen This Before"
Human underwriters rely on memory: "This looks like that Starlink launch from 2022."
Module 2 replicates this with a memory system.
After each pricing run, AION saves:
Mission summary (as vector embedding)
Key stats (orbit, mass, heritage, premium, risk band)
Coverage structure and operator profile
When a new mission arrives, the system searches for similar missions across three dimensions:
Semantic similarity (mission description and risk profile)
Configuration proximity (orbit, altitude ±100km, mass, launch vehicle)
Pricing band (premium within ±2%)
Result: Reference pricing for consistency. "We priced three similar LEO comms missions at 4.2–4.8%; this one at 4.5% is in line with portfolio precedent."
This creates an instant feedback loop: "We've seen this before." It ensures pricing consistency across the portfolio and prevents underwriters from starting from zero on every deal.
3d. Metric Explainability: No More "Trust Me"
In Module 1, metrics were black boxes. Module 2 makes them transparent.
Click any metric (failure_risk, premium, VaR, launch_phase_risk) and get:
The formula (e.g., Weibull β parameters, phase risk weightings)
The inputs used for this specific mission
Comparable values from similar missions
Links to methodology documentation
Example: Premium of 5.6% → Formula breakdown → Shows launch heritage factor (0.92), TRL adjustment (1.15), cyber gap loading (+0.8%) → Links to Weibull_Methodology.md and Heritage_Scoring.md
This turns the dashboard from a static display into a teaching tool for junior underwriters. They can see why the number is what it is, backed by methodology docs, not just LLM output.
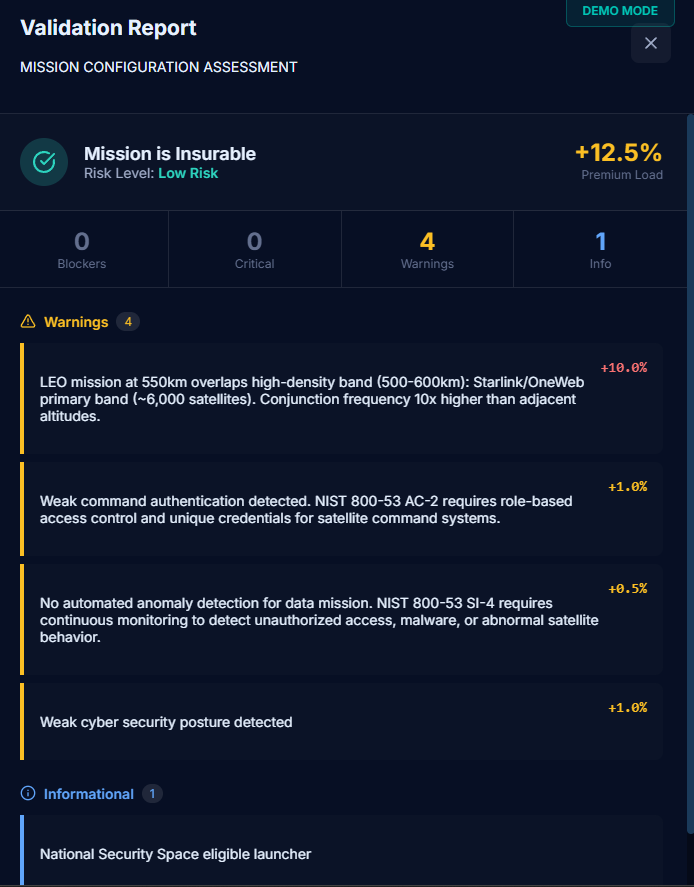
Why It Matters
For Underwriters
Module 2 delivers defensible decisions under scrutiny.
When a broker pushes back on a quote, or a regulator asks why you declined coverage, you aren't guessing. You have:
Regulatory citations for every validation flag
Portfolio precedent from similar missions
Methodology docs backing every metric
A regulator-ready narrative with sources
It's the difference between "the model says no" and:
"This mission violates ISO 24113 Clause 5.1; here are three comparable missions we declined for the same reason, and here's the regulatory framework we're operating under."
For AION as a Product
Module 1 proved I could build risk models.
Module 2 proves I understand how underwriters actually think: regulatory frameworks, portfolio consistency, explainability under pressure.
This isn't a tech demo built in isolation. It's a tool designed with underwriting logic baked in from the start:
22 validation rules catching what experienced underwriters would flag manually
Four Pillars framework mirroring how Lloyd's syndicates structure risk
Similar-missions search replicating institutional memory
Glass-box narratives that can be sent directly to brokers
For an employer like Relm, this shows systems thinking at the domain level, not just coding ability.
For My Portfolio
Together, M1 + M2 demonstrate:
M1: I can build Monte Carlo risk engines, phase-based models, and pricing logic
M2: I can layer regulatory intelligence, RAG pipelines, and explainability on top
Combined: I can ship production-ready systems fast (9 days for M2) with real business value
This is what the space insurance industry needs: someone who can move between quant modelling, regulatory compliance, and product design without translation layers.
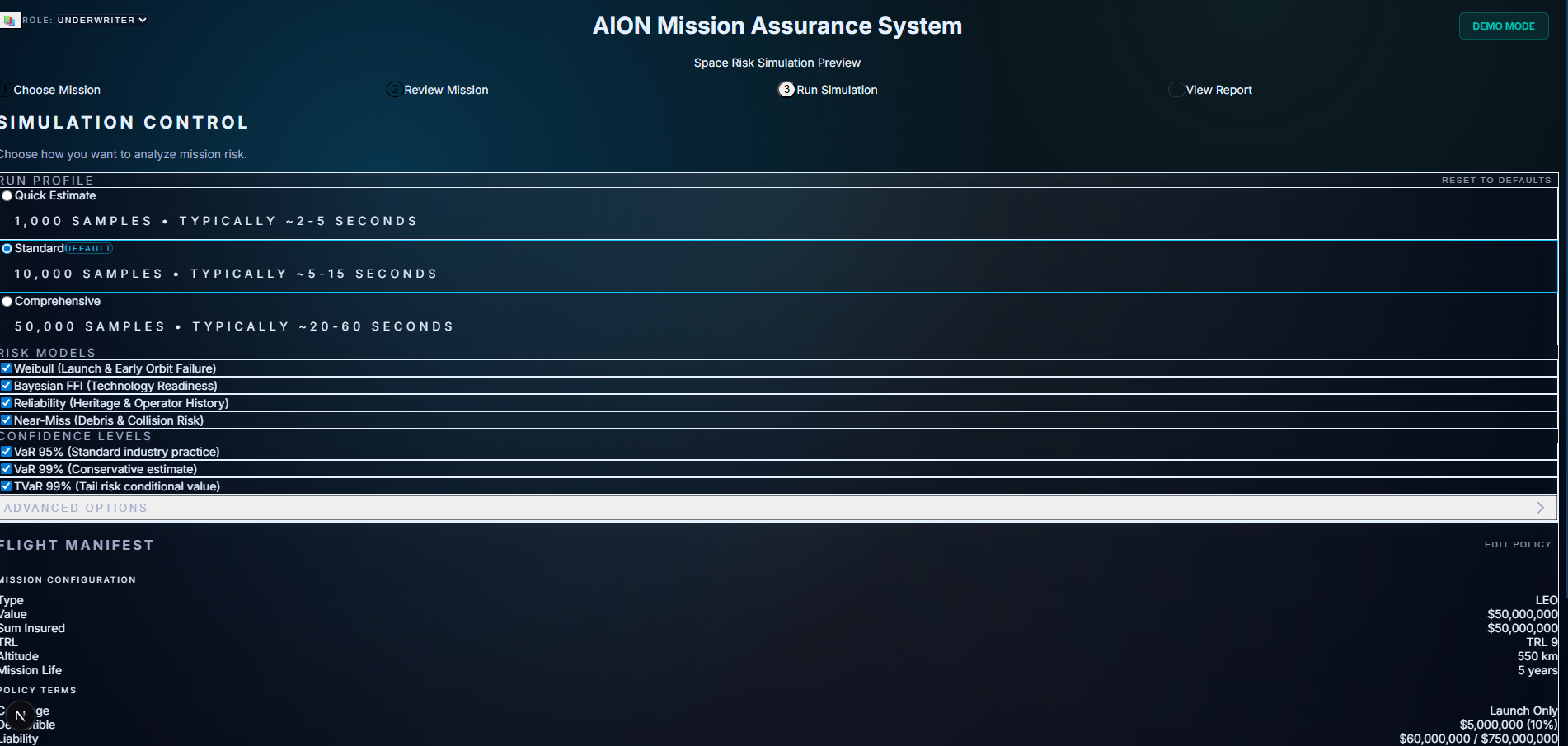
What's Next
Module 2 is frozen. The Context Engine is production-ready.
But AION isn't done. The full vision needs three more pieces.
Immediate: Broker Wizard Flow (In Progress)
Right now, the underwriter flow (M1 + M2) works end-to-end. Brokers need a different interface—simplified submission, portfolio view, and quote comparison.
I'm building the broker-facing flow now (NOVASPACE): a three-step submission wizard with cyber posture assessment, governance scoring, and product risk profiling. Cleaner inputs, batch quoting, and exportable deal sheets.
Next: Polish & Integration
Once the broker wizard is complete, I'll tighten the handoff between the two flows:
Broker submits → mission config + portfolio context
Underwriter reviews → validation flags + similar missions + M2 narrative
System recommends → GREEN / AMBER / RED with premium and terms
The goal is a fully joined-up submission-to-quote workflow across both interfaces.
Then: Module 3 — Parametric Engine
The final piece of the core stack: how do we pay claims?
Module 3 will handle:
Parametric trigger definitions (launch failure, orbit insertion, collision events)
Event stream integration (space weather, debris conjunctions, anomaly feeds)
Trigger clause justification (using M2's regulatory and technical context)
Claims automation once trigger conditions are met
At that point, AION becomes a full lifecycle space risk platform:
submission → validation → pricing → monitoring → claims.
Technical Stack & Key Metrics
Backend
FastAPI (Python 3.11)
PostgreSQL 15 + pgvector (HNSW vector index)
SQLAlchemy 2.0 + Alembic
OpenAI
text-embedding-3-small(embeddings)Anthropic Claude Sonnet (narrative generation)
Frontend
Next.js 14 + React 18
TypeScript 5+
Tailwind CSS 3+
Zustand (state management)
Module 2 Metrics
Timeline: 9 days (2–11 December 2025)
Effort: ~180 hours across 11 phases
Code: ~12,500 LOC (≈8K backend, 4.5K frontend)
Tests: 30 tests, 80%+ coverage, 100% pass rate
Rules: 22 validation rules
Data: 6
context_*database tablesAPI: 10+ dedicated Context Engine routes
Status: ✅ Frozen for V1

AION: Module 1 Phase 2
Phase 2 of AION’s Risk Engine was about moving from a working prototype to something an underwriter could actually trust. I rebuilt the core logic around survival curves, calibration, environmental sensitivities, and a clearer mission view to make risk reasoning easier, not flashier.
Building a Risk Engine That Underwriters Can Trust
Phase 1 of AION gave me something simple but valuable:
a loop that could take a mission, run a model, and explain its result.
Phase 2 raised the standard.
The question this time wasn’t “Can I build a risk model?” but:
“Can I build one an underwriter would trust for a first-pass view?”
That meant moving away from toy numbers and towards something closer to real insurance work: probability curves, calibrated priors, realistic failure rates, and a pricing engine that behaves like a disciplined actuarial tool, not a demo.
Opening the Model Up: Real Failure Curves
The first breakthrough in Phase 2 was replacing linear logic with proper survival analysis.
The engine now uses:
A Weibull lifetime curve
(infant mortality → stable phase → wear-out)A Bayesian update model for TRL and heritage
A reliability model tuned by orbit and launch vehicle
Hardware doesn’t fail in a straight line.
It fails according to curves, and capturing that shape immediately made the engine feel more aligned with historical space behaviour.
A positive example: fixing the inverted TRL priors.
In Phase 1, immature tech was being treated as safer — a comforting mistake.
Correcting it made the system more honest and more useful.
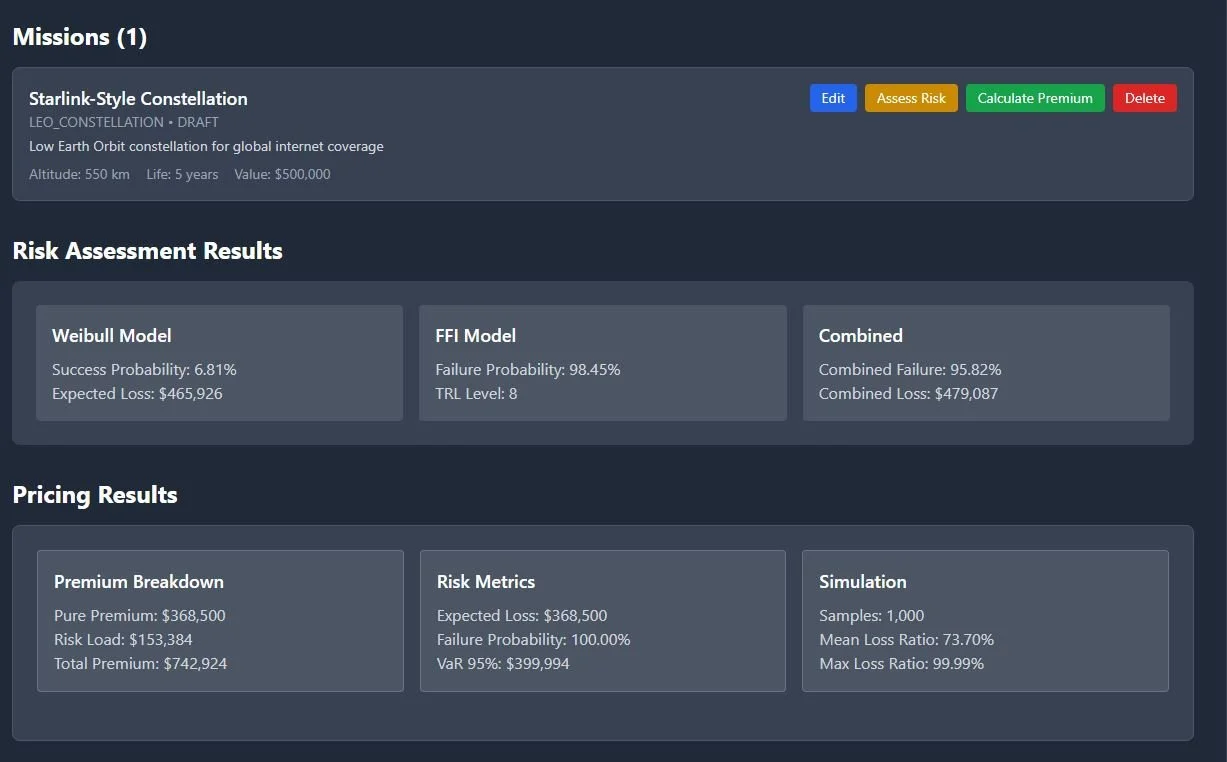
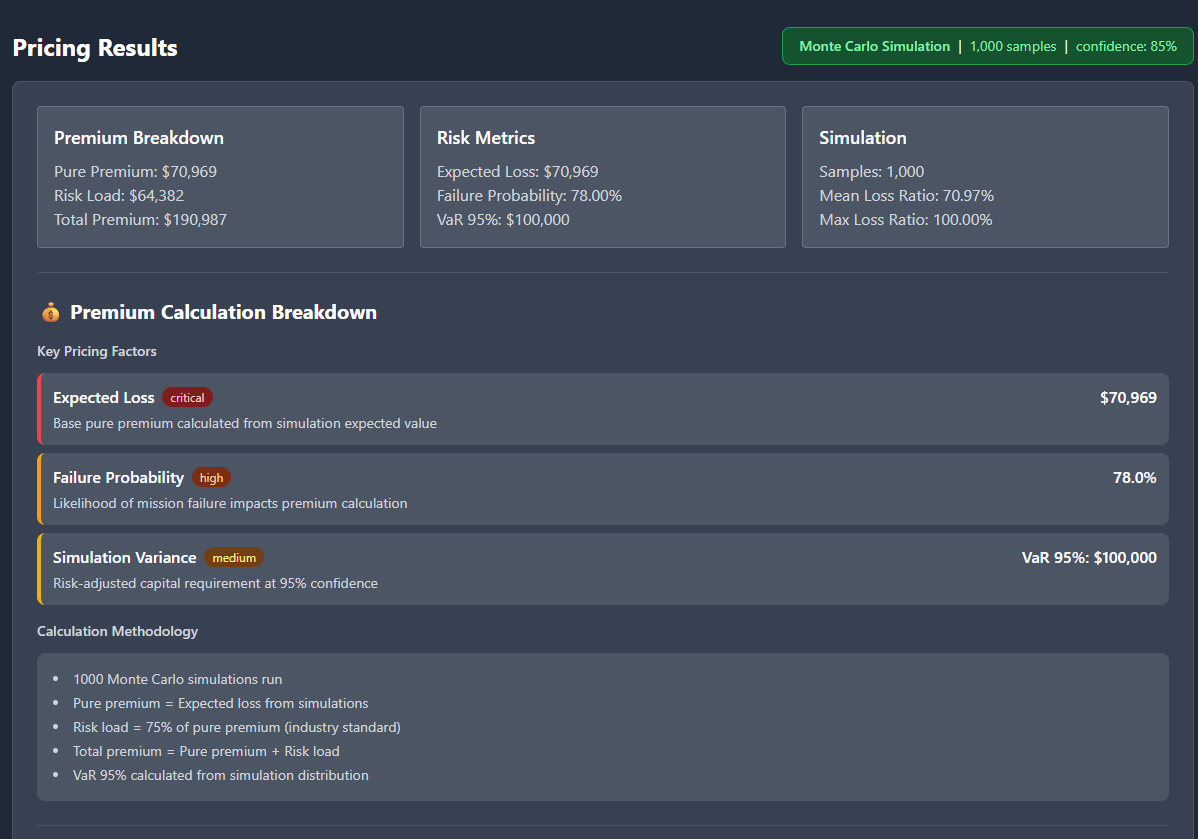
A Pricing Engine That Shows Its Working
Phase 2 introduced a Monte Carlo pricing engine with:
Premium bands
VaR95 / VaR99
Tail loss behaviour
Decomposition across pure, risk, catastrophe, expense, profit
Calibration against simple industry bands
(LEO: 5–15% of SI, GEO: 1–5%)
The engine now runs 50,000 quantile samples (seeded for reproducibility) and treats price as a consequence of the probability curve, not a lookup table.
The most important addition was the explicit premium decomposition:
Here is what drove the risk.
Here is the impact of each adjustment.
Here is why the premium sits here.
It forced me to think like an underwriter rather than a developer.
Calibrated Priors: Bringing Discipline to the Numbers
Phase 2 introduced a more disciplined calibration layer:
Blend weighting: 0.09·model + 0.91·prior
Orbit caps: LEO 0.12, GEO 0.06
Realistic failure rates: Falcon 9 ≈ 97.7% success
Severity modelling:
20% total loss
80% partial loss (Beta distribution, 10–40% SI)
These numbers aren’t perfect, but they stop the model from being overconfident just because the Monte Carlo chart looks pretty.
Calibration isn’t a cosmetic step — it’s a form of intellectual honesty.
Adding Environmental Sensitivities
Space isn’t a static environment, so the model shouldn’t be either.
Phase 2 added:
Conjunction density → increases probability
Solar activity (solar_high) → increases severity and thickens the tail
These modifiers aren’t meant to be hyper-accurate.
They’re meant to teach the right behaviour:
Risk is dynamic.
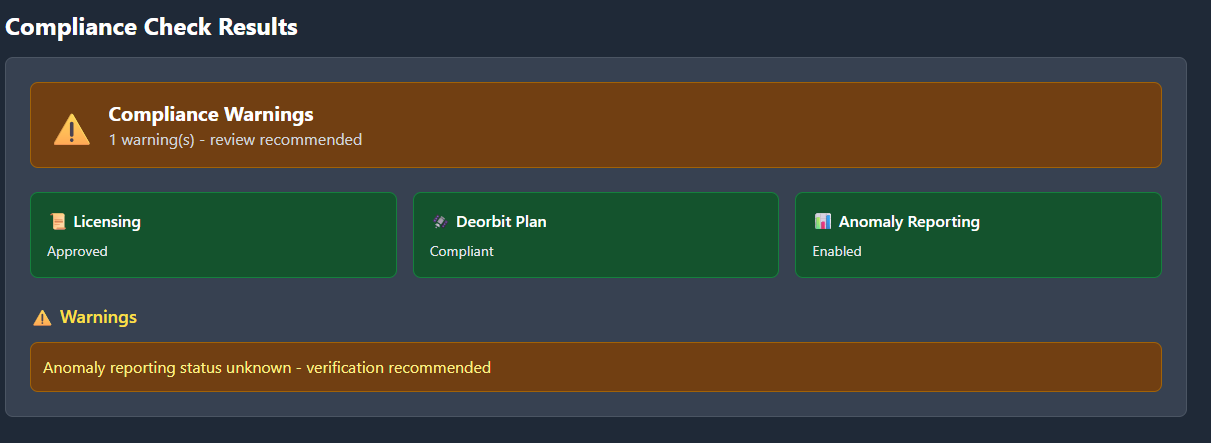
Compliance: The First Signs of Real-World Constraints
I added a light compliance layer that addresses the following areas:
licensing
deorbit planning
anomaly reporting
grey-zone mapping (
fallbacks.yaml)
If a mission is unlicensed, the model applies a simple, transparent rule:
+10% premium, via a feature flag.
It’s the first time AION began to link technical risk with regulatory exposure — something Phase 1 ignored entirely.
A Mission View That Reduces Cognitive Load
Phase 2 reorganised the UI into a single mission workbench:
Mission profile
Risk band + confidence
Pricing band + decomposition
Compliance flags
Environmental modifiers
An assumptions drawer showing the engine’s reasoning
Adjustment chips explaining signal impacts
It’s not polished.
But it has a calm structure you can actually think inside — which is more important at this stage than visual flair.
Reducing cognitive load was the whole point.
What This Phase Taught Me
Modelling is a negotiation with reality.
Every fix — inverted priors, overflow issues, curve tuning — revealed where intuition diverged from the world.
Underwriters don’t want a number; they want the reasoning trace.
The more transparent the model became, the more confident I became in its behaviour.
Calibration is honesty encoded as math.
Small parameters grounded the system more than any big feature.
Tools shape thinking.
Designing a single mission view changed the way I built the model itself.
What Phase 2 Sets Up
Phase 2 didn’t finish the engine.
It clarified the foundation.
It taught me to build something that:
behaves predictably
explains itself rigorously
stays within calibrated bounds
is structured for future extension
can sit in front of a professional without apology
Phase 3 will focus on refining the narrative layer:
clearer assumptions, more consistent reasoning, and a tighter link between risk, environment, compliance, and price.
But for the first time, the engine feels usable.
Not finished.
Not perfect.
But grounded enough to build on with confidence.
AION: Module 1 Phase 1
Why I Started
After attending fintech and space conferences, I wanted to connect the ideas I was hearing with something practical.
AION began as a curiosity project — a way to learn how risk, data, and AI could come together in the space industry.
It isn’t a company or a product. It’s a sandbox for learning: I build, test, break, and rebuild to understand how systems like space insurance and orbital analytics might actually work.
What I Set Out to Build
The goal of Phase 1 was simple:
Take a satellite mission, score its risk, price its insurance, and explain why.
That meant creating:
✅ API contracts — stable, validated endpoints for missions, scores, and pricing.
✅ A retrieval system (RAG) — to search through documents and show where each risk factor came from.
✅ A transparent UI — where results were explainable, not black-box.
I also wanted everything to run locally through Docker in under three seconds.
If it could do that — and tell me why a mission scored 72 instead of 85 — Phase 1 would be complete.
1️⃣ Mission Input Interface — Enter a satellite profile and select orbit/class.

2️⃣ Assessment Result — Risk = 72 | Confidence = 62 % | Premium ≈ $1.28 M.
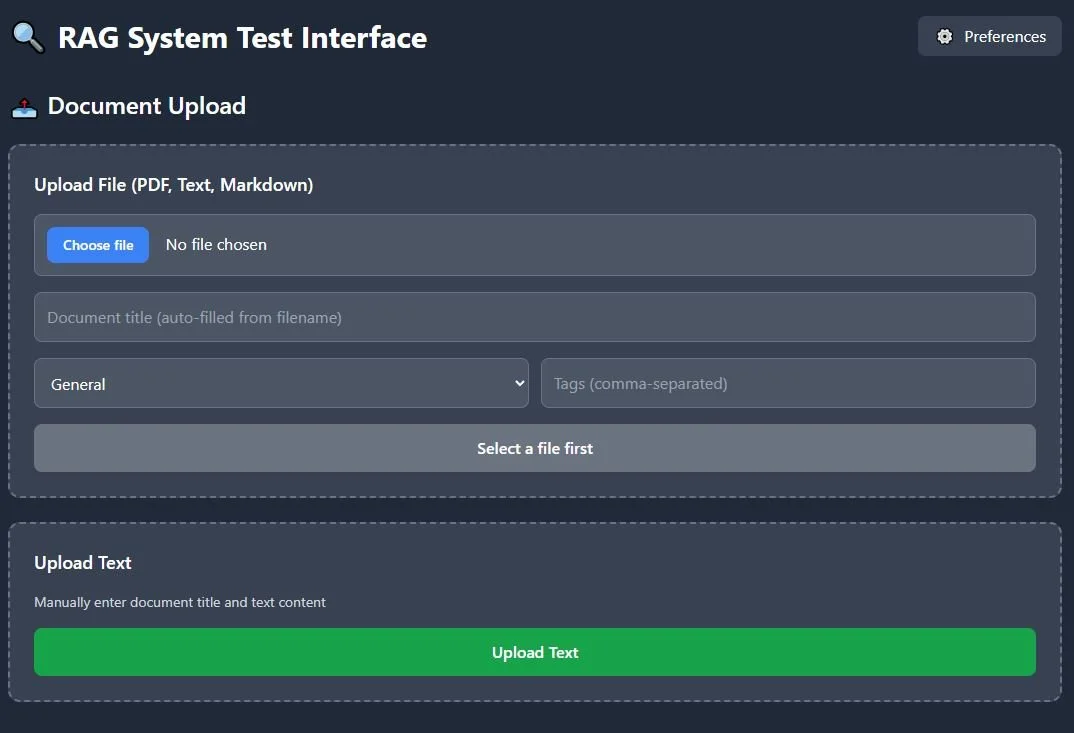
3️⃣ RAG Upload — Upload PDFs or notes; system tags and embeds them.
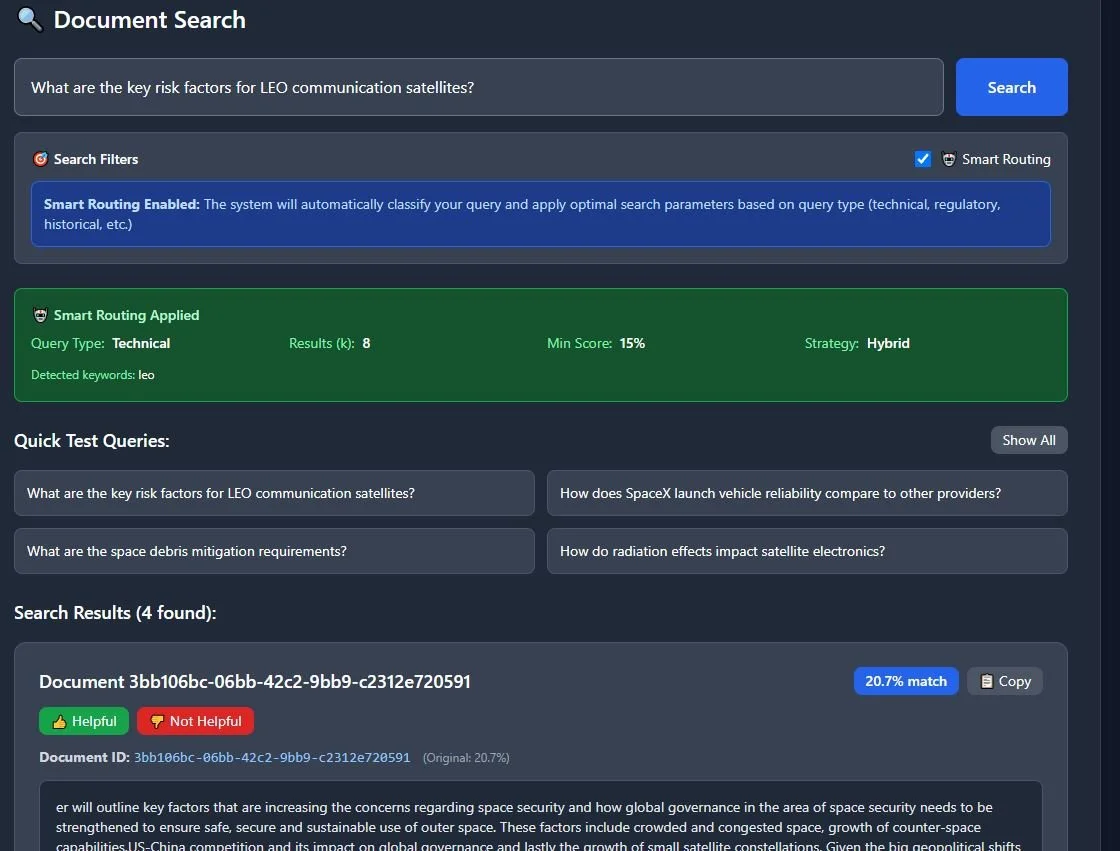
4️⃣ Smart Search — Ask: “What are key risk factors for LEO satellites?”
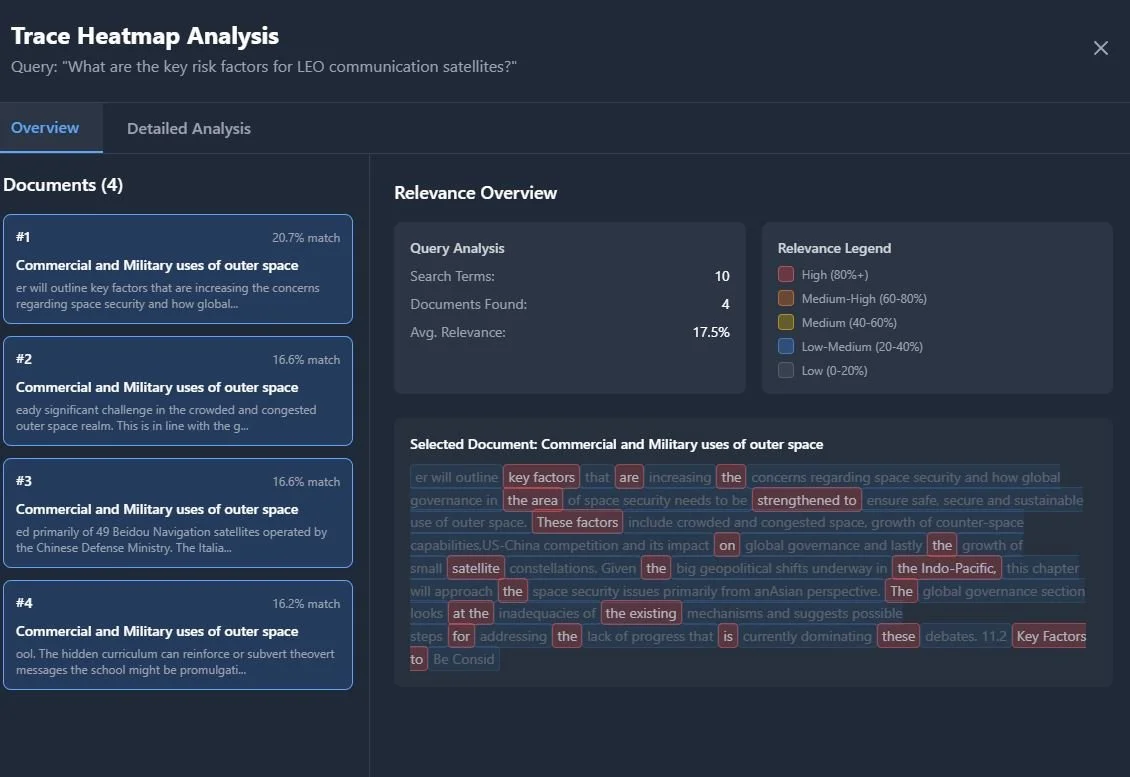
5️⃣ Heatmap View — Visual relevance highlights show why the answer appears.
What Went Well
Full working loop. The app can score and price a mission in under three seconds.
Explainability first. Every result shows its sources and reasoning.
End-to-end integration. Backend ↔ Frontend ↔ Database ↔ UI now talk fluently.
Workflow discipline. I learned to structure projects in phases, document endpoints, and validate inputs like a professional build.
Coding growth. Building this with FastAPI, Next.js, and Docker taught me more about engineering logic than any course so far.
Challenges & Fixes
Every phase exposed a new gap in my understanding — and that was the point.
CORS errors: fixed with FastAPI middleware.
Docker caching: rebuilt containers with
--buildto reflect code updates.Database migrations: corrected Alembic paths and built a fallback SQL setup.
Tailwind styling not updating: cleaned config paths.
PDF titles missing in search results: surfaced document metadata in responses.
Tools I Used
🧠 FastAPI + PostgreSQL for the backend
⚙️ Next.js + TypeScript + Tailwind CSS for the frontend
📦 Docker Compose for local orchestration
🤖 Cursor as my AI-assisted code editor
I discovered it through the developer community on X (formerly Twitter), where I come across the latest tools from developers. Cursor helps me think faster and experiment more—it’s like having a silent coding partner that keeps me learning.
My workflow is simple: I read/learn something → have an idea → try building it → learn through debugging.
Each step teaches me something about space tech, AI, and my own problem-solving style.
Cursor integrated chat and editor.
What I Learned
Phase 1 taught me that:
Building forces clarity.
A clear UI is as important as accurate data.
Every technical barrier (CORS, caching, schema errors) is an opportunity to learn a concept properly.
Above all, I learnt that explaining your logic is a feature, not an afterthought.
What’s Next (Phase 2)
Phase 2 will focus on:
Integrating real orbital data — debris, weather, mission classes.
Experimenting with Bayesian and Monte-Carlo models for risk.
Expanding explainability dashboards with clearer visuals and exports.
Making the tool modular for future AI-driven insurance experiments.