The Lab
Experiments in quantifying the uninsurable.
I am currently building AION, an AI-native underwriting engine designed to bridge the gap between technical space data and insurance capital.
This feed documents the build in real-time: the technical bottlenecks, the architectural pivots, and the solutions required to deploy a working Risk Engine.
Active Module: M2 (Context & Explainability)
AION: Module 2 — From Black Box to Glass Box
The Problem: Calculators Aren't Enough
Module 1 gave you numbers. You could configure a mission, run the Monte Carlo model, and get a premium out the other side. It was fast. It was mathematically sound.
But in speciality insurance, numbers aren't enough.
A junior underwriter can run a model. A senior underwriter knows the model is only 10% of the story. They ask:
"Is this mission even legal under current UKSA regulations?"
"Have we seen a similar satellite configuration fail in LEO before?"
"Is this operator sanctioned?"
"Why is the premium 12.4%?"
If your system can't answer those questions—if it just says "trust me"—it's useless in the Lloyd's market. You need to defend every quote to capital providers, brokers, and regulators.
Module 1 turned AION into a risk brain.
Module 2 is the difference between a calculator and a senior underwriter.
It's the Context Engine: the piece that checks regulatory compliance, remembers past missions, explains every metric, and cites its sources. It turns AION from "here's a number" into "here's a defensible underwriting decision with regulatory backing and portfolio precedent."
Timeline: December 2–11, 2025 (9 days, ~180 hours) · Status: ✅ Frozen for V1

What I Built: The Context Engine
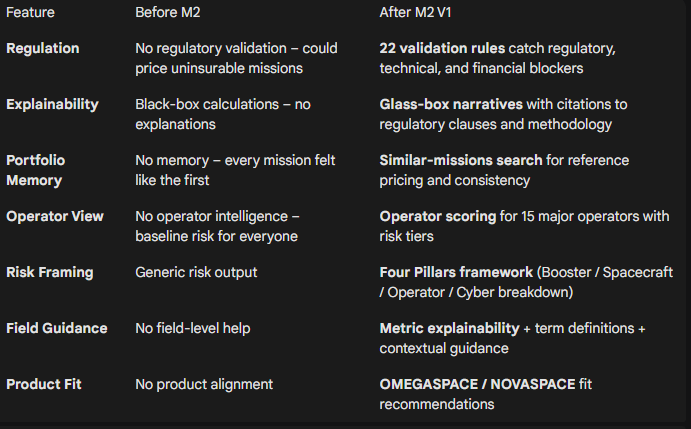
Module 2 delivers four core capabilities:
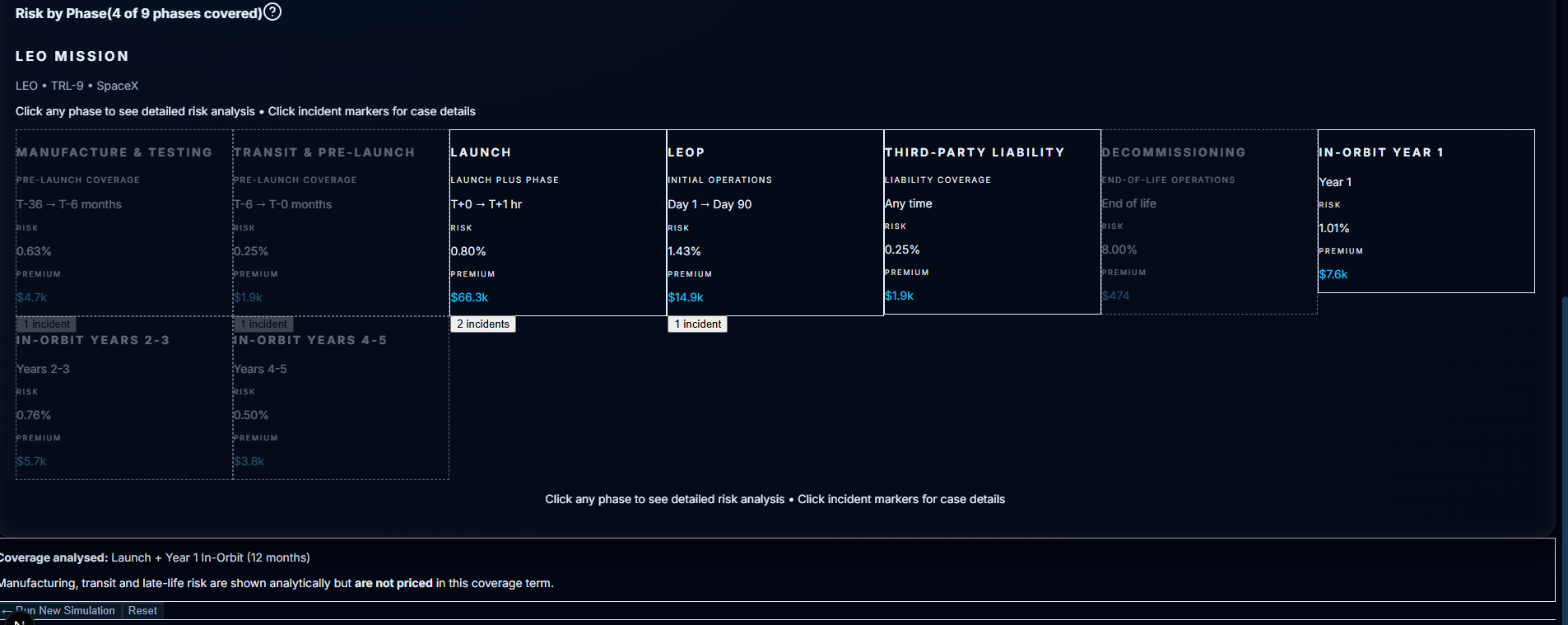
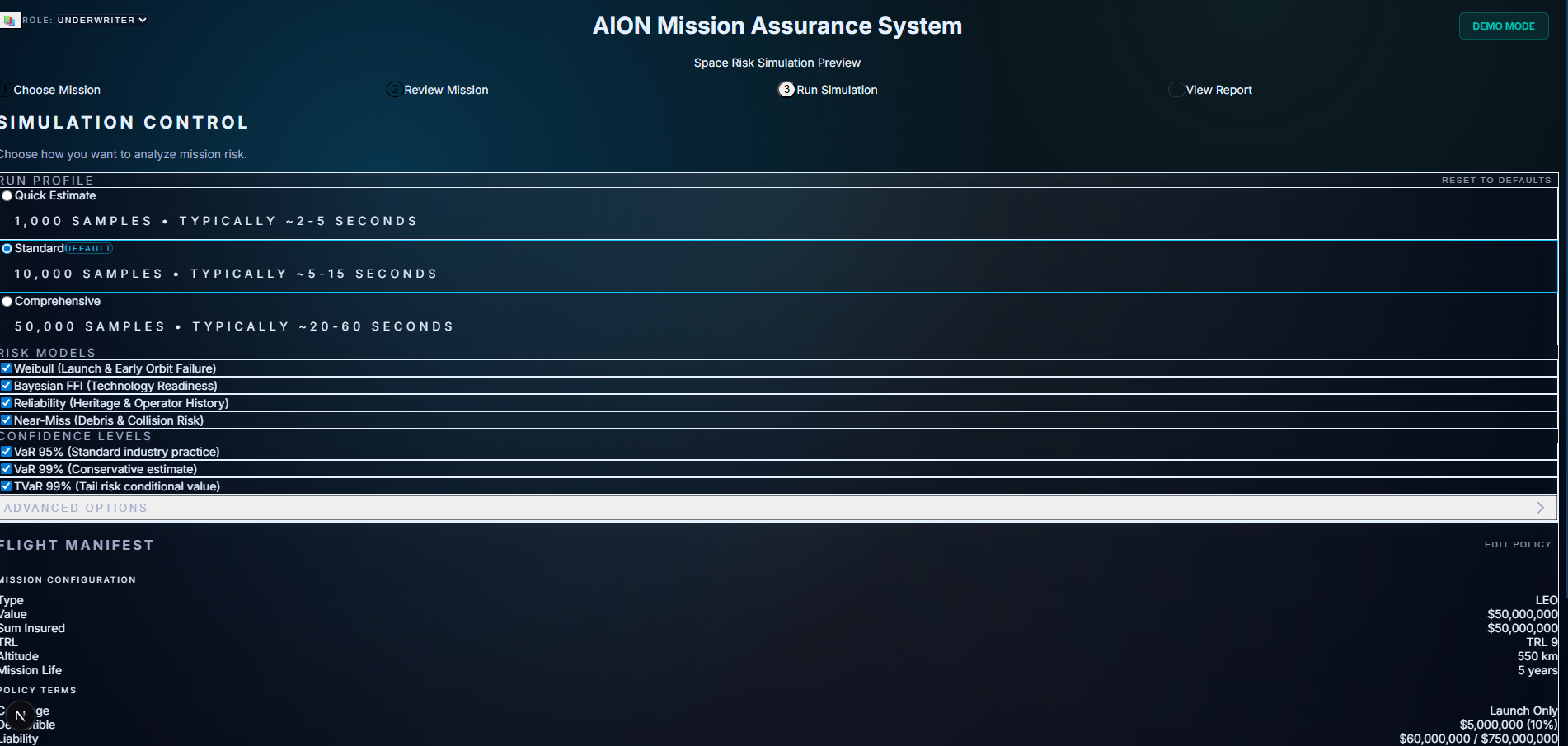
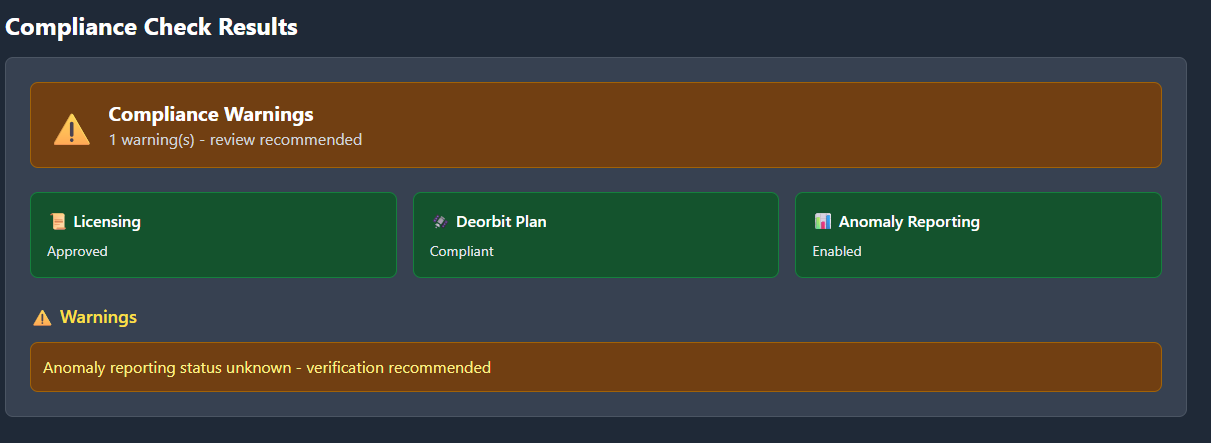
1. Regulatory Validation (22 Rules)
A rule engine that checks missions against international regulations, market access restrictions, technical safety requirements, and financial viability before pricing runs.
Traffic-light system (GREEN / AMBER / RED)
Each flag backed by citations to specific regulatory clauses
2. Hybrid Search + Glass-Box Narrative
A search engine that fuses:
vector similarity (semantic meaning)
BM25 keyword search
recency
reliability scoring
Every risk assessment comes with a narrative: bullet points, regulatory citations, and methodology references.
Not just "premium is 5.6%" but "here's why, here's the clause, here's the comparable mission".
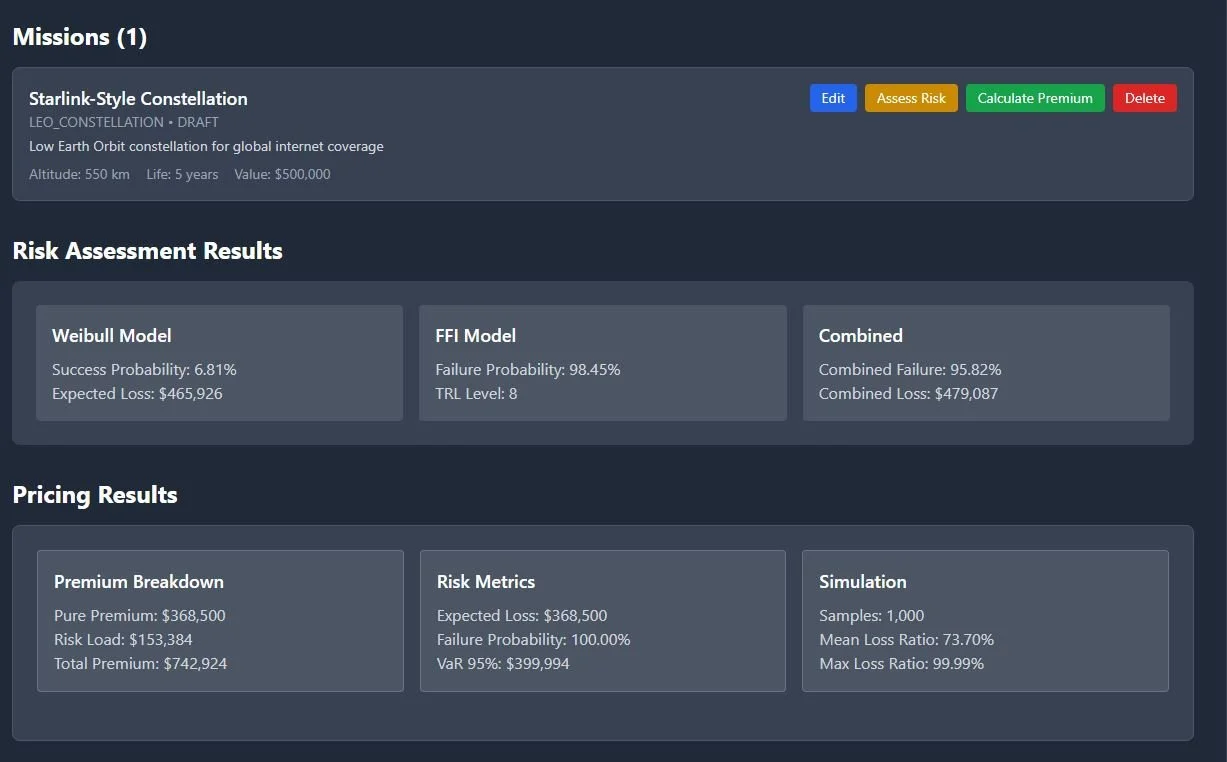
3. Portfolio Memory (Similar Missions)
Every priced mission is saved as an embedding.
When a new submission comes in, the system finds similar missions by orbit, mass, heritage, and premium band.
"We've seen this before" → instant reference pricing and consistency.
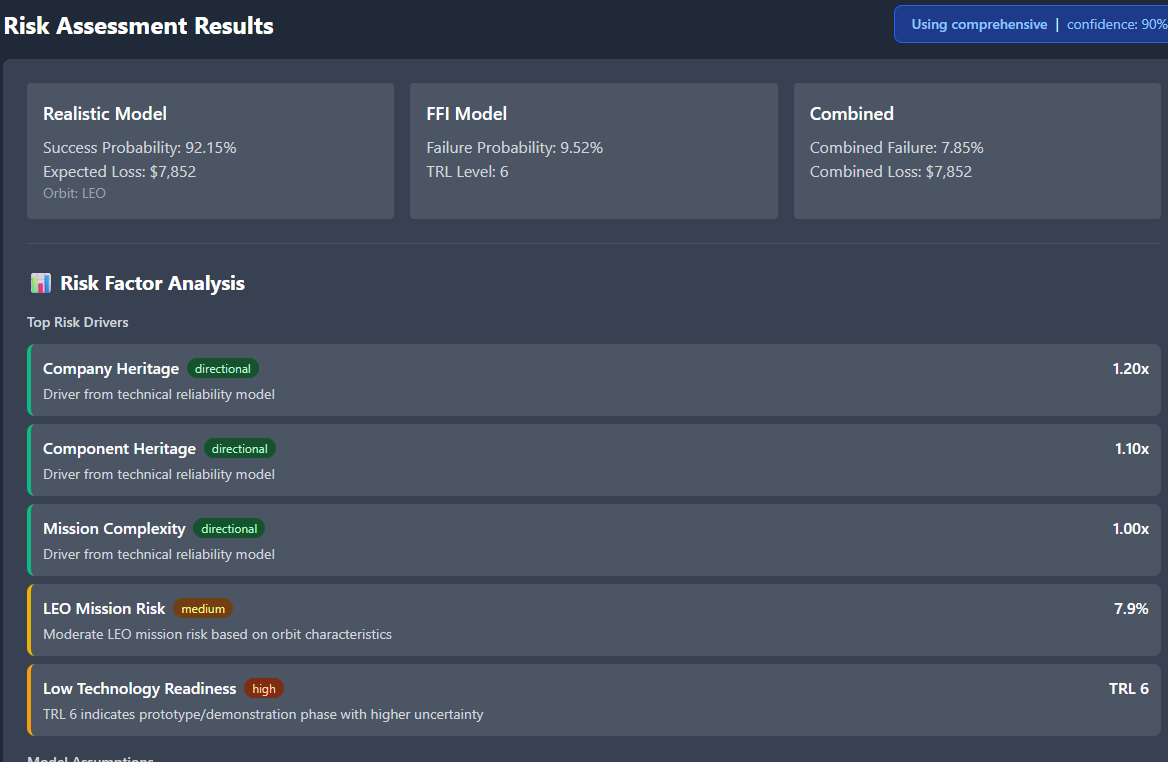
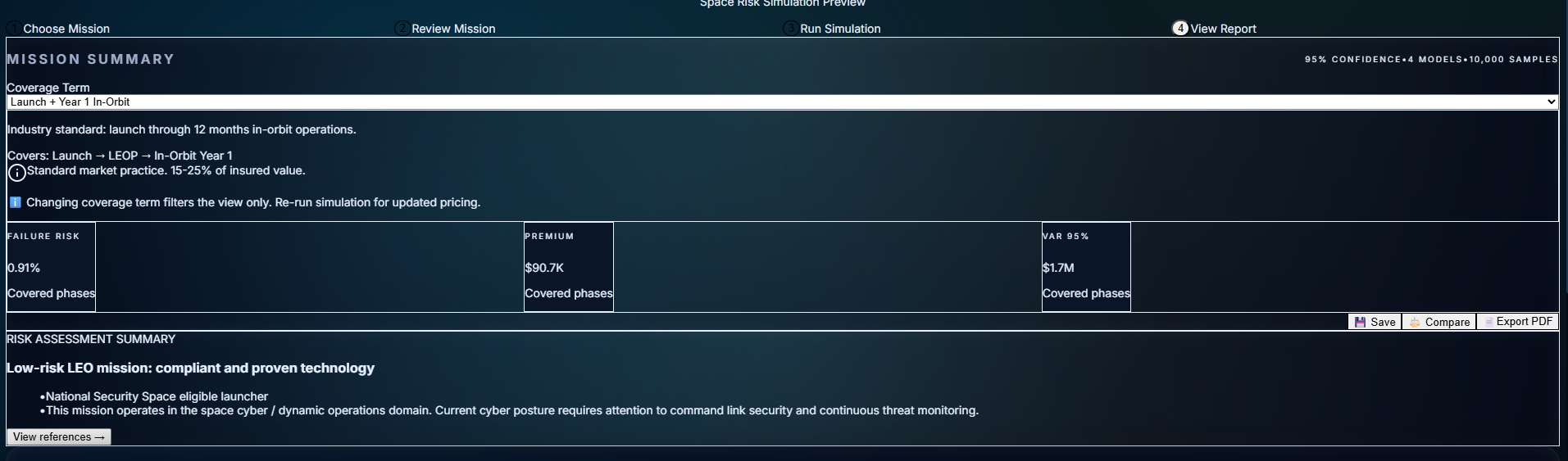
4. Metric Explainability
Click any metric (failure_risk, premium, VaR, phase risks) and get:
the formula used
the inputs for this mission
comparable values from similar missions
links back to methodology docs
It takes AION from black box to glass box.
Before Module 2 vs After Module 2
Module 2 is now FROZEN for V1.
This isn't ongoing tinkering—it's a shipped, production-ready module with 30 passing tests, 80%+ coverage, and complete documentation.
Next step: build on top of it with Module 3.
How It Works: Inside the Context Engine
Building a glass box isn't just prompt engineering. It requires architecture that forces the AI to check its facts before it speaks.
3a. Regulatory Validation: The Gatekeeper
Module 2's rule engine runs before any pricing logic. It applies 22 validation rules across four categories:
Regulatory compliance: ISO 24113 (25-year disposal), FCC 5-year deorbit, UKSA licensing
Market access: ITAR/EAR restrictions (China, India, Vietnam, Thailand)
Financial viability: Flags operators with <6 months funding runway
Sanctions & export control: LMA 3100A sanctions clause, US content thresholds
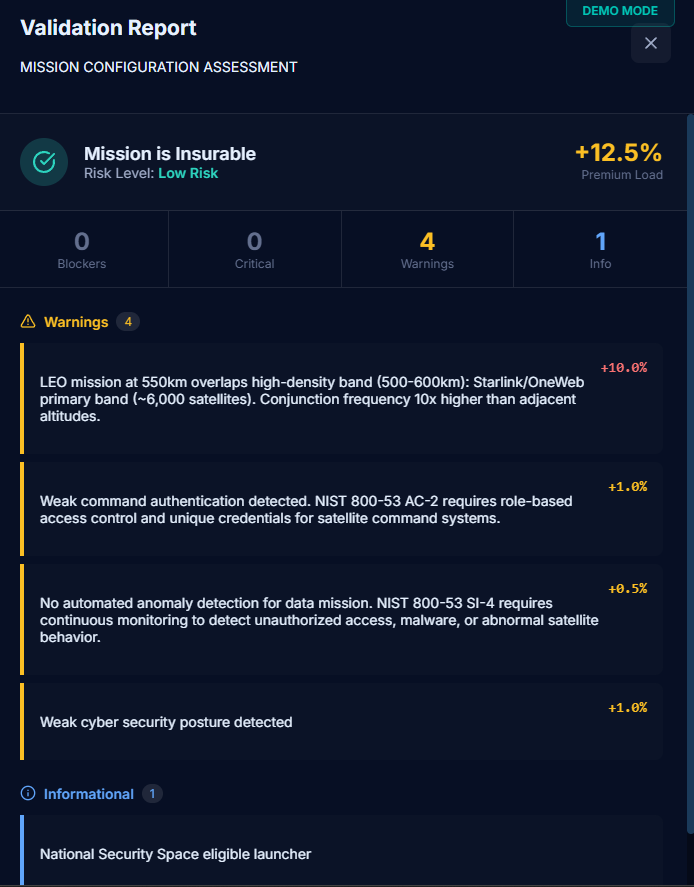
Each mission gets a traffic light (GREEN/AMBER/RED). RED flags block the quote entirely. AMBER flags add premium loadings with regulatory justification.
Example: A LEO constellation with a Chinese parent company triggers the Foreign Ownership Rule → AMBER flag → cites specific ITAR clause → adds 15% premium load.
This isn't an LLM guessing. It's deterministic logic checking real regulatory requirements. It stops you from wasting capital on uninsurable risk.
3b. Hybrid Search + Glass-Box Narrative
The biggest risk in AI for insurance isn't hallucination—it's opacity.
To solve this, I built a hybrid search engine that fuses:
Vector search (pgvector HNSW) for semantic similarity
BM25 keyword search (PostgreSQL full-text) for exact clause matches
Reciprocal Rank Fusion to merge results
Weighted scoring: 40% semantic + 30% keyword + 15% recency + 15% reliability
The corpus includes UKSA regulations, ISO standards, FCC rules, ESA guidelines, and internal methodology docs (Weibull parameters, pricing logic, Monte Carlo VaR).
Every risk narrative comes with citations. Not "this mission is risky because AI said so" but "this mission triggers Clause 5.1 of ISO 24113 because the deorbit plan exceeds 25 years."
The system doesn't just find close text—it finds the most trustworthy clauses for the specific mission configuration.
3c. Portfolio Memory: "We've Seen This Before"
Human underwriters rely on memory: "This looks like that Starlink launch from 2022."
Module 2 replicates this with a memory system.
After each pricing run, AION saves:
Mission summary (as vector embedding)
Key stats (orbit, mass, heritage, premium, risk band)
Coverage structure and operator profile
When a new mission arrives, the system searches for similar missions across three dimensions:
Semantic similarity (mission description and risk profile)
Configuration proximity (orbit, altitude ±100km, mass, launch vehicle)
Pricing band (premium within ±2%)
Result: Reference pricing for consistency. "We priced three similar LEO comms missions at 4.2–4.8%; this one at 4.5% is in line with portfolio precedent."
This creates an instant feedback loop: "We've seen this before." It ensures pricing consistency across the portfolio and prevents underwriters from starting from zero on every deal.
3d. Metric Explainability: No More "Trust Me"
In Module 1, metrics were black boxes. Module 2 makes them transparent.
Click any metric (failure_risk, premium, VaR, launch_phase_risk) and get:
The formula (e.g., Weibull β parameters, phase risk weightings)
The inputs used for this specific mission
Comparable values from similar missions
Links to methodology documentation
Example: Premium of 5.6% → Formula breakdown → Shows launch heritage factor (0.92), TRL adjustment (1.15), cyber gap loading (+0.8%) → Links to Weibull_Methodology.md and Heritage_Scoring.md
This turns the dashboard from a static display into a teaching tool for junior underwriters. They can see why the number is what it is, backed by methodology docs, not just LLM output.
Why It Matters
For Underwriters
Module 2 delivers defensible decisions under scrutiny.
When a broker pushes back on a quote, or a regulator asks why you declined coverage, you aren't guessing. You have:
Regulatory citations for every validation flag
Portfolio precedent from similar missions
Methodology docs backing every metric
A regulator-ready narrative with sources
It's the difference between "the model says no" and:
"This mission violates ISO 24113 Clause 5.1; here are three comparable missions we declined for the same reason, and here's the regulatory framework we're operating under."
For AION as a Product
Module 1 proved I could build risk models.
Module 2 proves I understand how underwriters actually think: regulatory frameworks, portfolio consistency, explainability under pressure.
This isn't a tech demo built in isolation. It's a tool designed with underwriting logic baked in from the start:
22 validation rules catching what experienced underwriters would flag manually
Four Pillars framework mirroring how Lloyd's syndicates structure risk
Similar-missions search replicating institutional memory
Glass-box narratives that can be sent directly to brokers
For an employer like Relm, this shows systems thinking at the domain level, not just coding ability.
For My Portfolio
Together, M1 + M2 demonstrate:
M1: I can build Monte Carlo risk engines, phase-based models, and pricing logic
M2: I can layer regulatory intelligence, RAG pipelines, and explainability on top
Combined: I can ship production-ready systems fast (9 days for M2) with real business value
This is what the space insurance industry needs: someone who can move between quant modelling, regulatory compliance, and product design without translation layers.
What's Next
Module 2 is frozen. The Context Engine is production-ready.
But AION isn't done. The full vision needs three more pieces.
Immediate: Broker Wizard Flow (In Progress)
Right now, the underwriter flow (M1 + M2) works end-to-end. Brokers need a different interface—simplified submission, portfolio view, and quote comparison.
I'm building the broker-facing flow now (NOVASPACE): a three-step submission wizard with cyber posture assessment, governance scoring, and product risk profiling. Cleaner inputs, batch quoting, and exportable deal sheets.
Next: Polish & Integration
Once the broker wizard is complete, I'll tighten the handoff between the two flows:
Broker submits → mission config + portfolio context
Underwriter reviews → validation flags + similar missions + M2 narrative
System recommends → GREEN / AMBER / RED with premium and terms
The goal is a fully joined-up submission-to-quote workflow across both interfaces.
Then: Module 3 — Parametric Engine
The final piece of the core stack: how do we pay claims?
Module 3 will handle:
Parametric trigger definitions (launch failure, orbit insertion, collision events)
Event stream integration (space weather, debris conjunctions, anomaly feeds)
Trigger clause justification (using M2's regulatory and technical context)
Claims automation once trigger conditions are met
At that point, AION becomes a full lifecycle space risk platform:
submission → validation → pricing → monitoring → claims.
Technical Stack & Key Metrics
Backend
FastAPI (Python 3.11)
PostgreSQL 15 + pgvector (HNSW vector index)
SQLAlchemy 2.0 + Alembic
OpenAI
text-embedding-3-small(embeddings)Anthropic Claude Sonnet (narrative generation)
Frontend
Next.js 14 + React 18
TypeScript 5+
Tailwind CSS 3+
Zustand (state management)
Module 2 Metrics
Timeline: 9 days (2–11 December 2025)
Effort: ~180 hours across 11 phases
Code: ~12,500 LOC (≈8K backend, 4.5K frontend)
Tests: 30 tests, 80%+ coverage, 100% pass rate
Rules: 22 validation rules
Data: 6
context_*database tablesAPI: 10+ dedicated Context Engine routes
Status: ✅ Frozen for V1

AION: Module 1 Phase 3-5
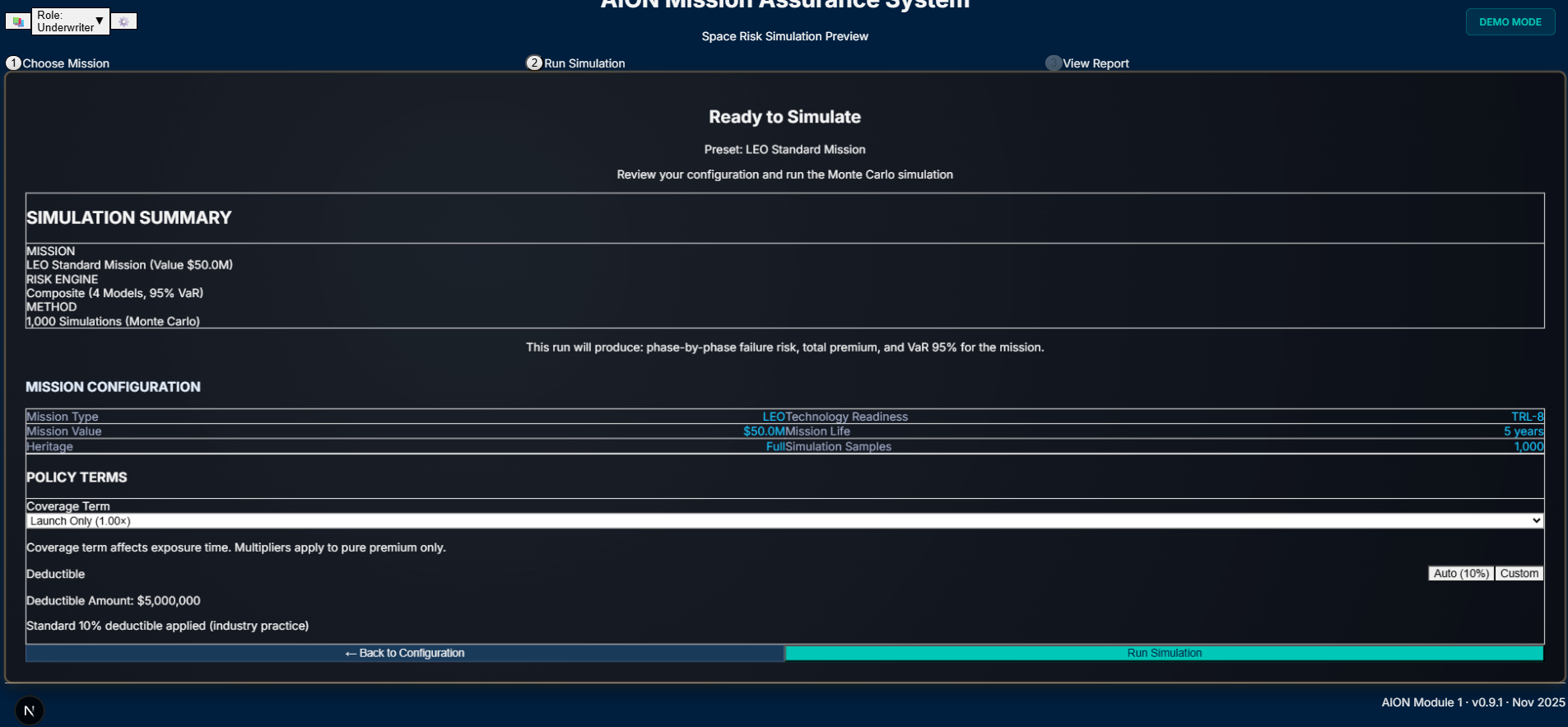
By the end of Phase 2, AION's risk engine could model realistic failure curves and price missions—but it wasn't production-ready. Phases 3, 4, and 5 transformed it from prototype to platform: 7 phase-specific actuarial models, regulatory compliance tracking, Lloyd's-grade UI, and <0.3s response times. Built using AI agent orchestration across research, planning, and execution. The result: a dependable underwriting workbench that real underwriters can trust. This is the story of that transformation—the obstacles, the iterations, and the systems thinking that made it possible.
From Prototype to Production: Building an Underwriting Engine
By the end of Phase 2, AION's risk engine could model realistic failure curves, price missions, and explain its reasoning.
That was a milestone — but it still wasn't a tool an underwriter could rely on day-to-day.
The gap between "working model" and "production system" turned out to be wider than I expected. Phases 3, 4, and 5 were about closing it.
These phases weren't about training new models or adding clever features. They were about turning a model into a system: stable, secure, testable, exportable, and usable.
AION had to shift from a prototype into something with structure, memory, repeatability, and the beginnings of operational discipline.
Here's how that transformation unfolded.
Phase 3 — Systemisation: Modeling How Insurance Floors Actually Work
Phase 3 focused on building the spine of Module 1: the architecture that would let this engine operate inside a real underwriting syndicate.
This wasn't just technical refactoring—it was modeling how insurance floors actually work.
A Unified Architecture
I consolidated the entire module behind a single flow:
Mission → Risk Engine → Pricing Engine → Explainability → Exports/UI
This introduced clean separation between:
Technical risk
Business factors
Compliance constraints
Environmental modifiers
Explainability
Everything finally pointed in the same direction. The engine could now answer questions like: "Is this mission risky because of the tech, or because of the operator's track record?" Those layers were finally distinct.
RBAC: Permissions That Understand Hierarchy
I implemented Role-Based Access Control (RBAC), distinguishing between Viewers, Analysts, and Underwriters.
This wasn't just permission bits; it was about modeling the actual hierarchy of an insurance floor:
A Viewer can see assessments
An Analyst can price missions
But only an Underwriter can approve exports and sign off on quotes
Small detail, but it signals that AION understands the business, not just the math.
A Proper API Layer
The API now has:
Versioned routes (
/api/v1/...)Strict request/response schemas
Predictable validation
Stable error shapes
Once the schema was locked, downstream components stopped breaking. This was a small change with a huge effect: integration became stable.
The Orchestrator Pattern
The Risk Engine became modular, predictable, and extensible.
Each model (Weibull, Bayesian, Reliability, Environment) now plugs into a single orchestrator that handles:
Model execution
Graceful fallback
Agreement scoring
Normalisation
Unified output
This eliminated entire categories of bugs and made calibration easier.
Support for Multiple Mission Types
Phase 3 introduced structured support for LEO, MEO, and GEO—each with its own logic and failure behaviour.
This removed one of the biggest silent flaws from early versions: treating all missions as interchangeable.
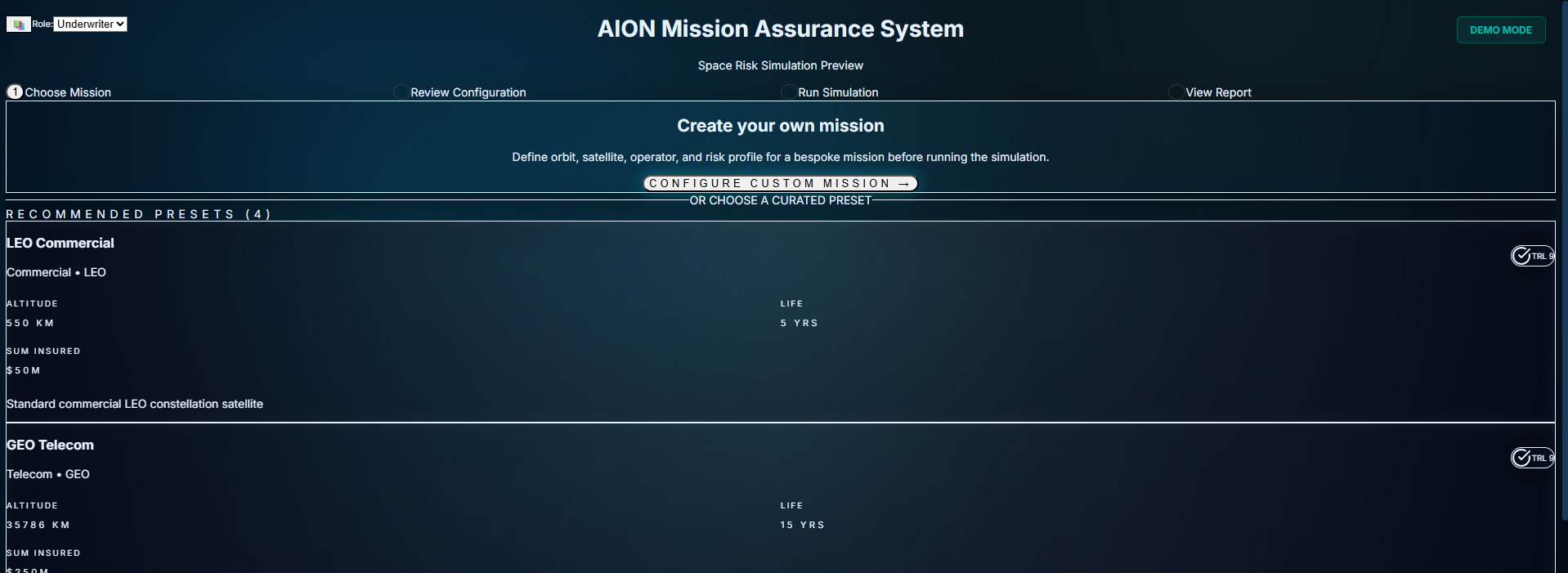
Phase 4 — Iteration: Building the Underwriting Workbench
Phase 4 was the most demanding phase of Module 1 so far.
It wasn't about algorithms—it was about iteration. Dozens of small sprints. Daily refinements. Continuous rewrites of the UI and logic surfaces until things felt consistent.
It was the closest experience yet to real product building.
The UI Overhaul: Making Risk Legible
Phase 4 forced me to take the UI seriously.
I'd been treating it as a wrapper around the models, but every time I tested the flow, I'd lose track of where in the mission lifecycle the risk was coming from. The interface wasn't just unclear—it was hiding the logic.
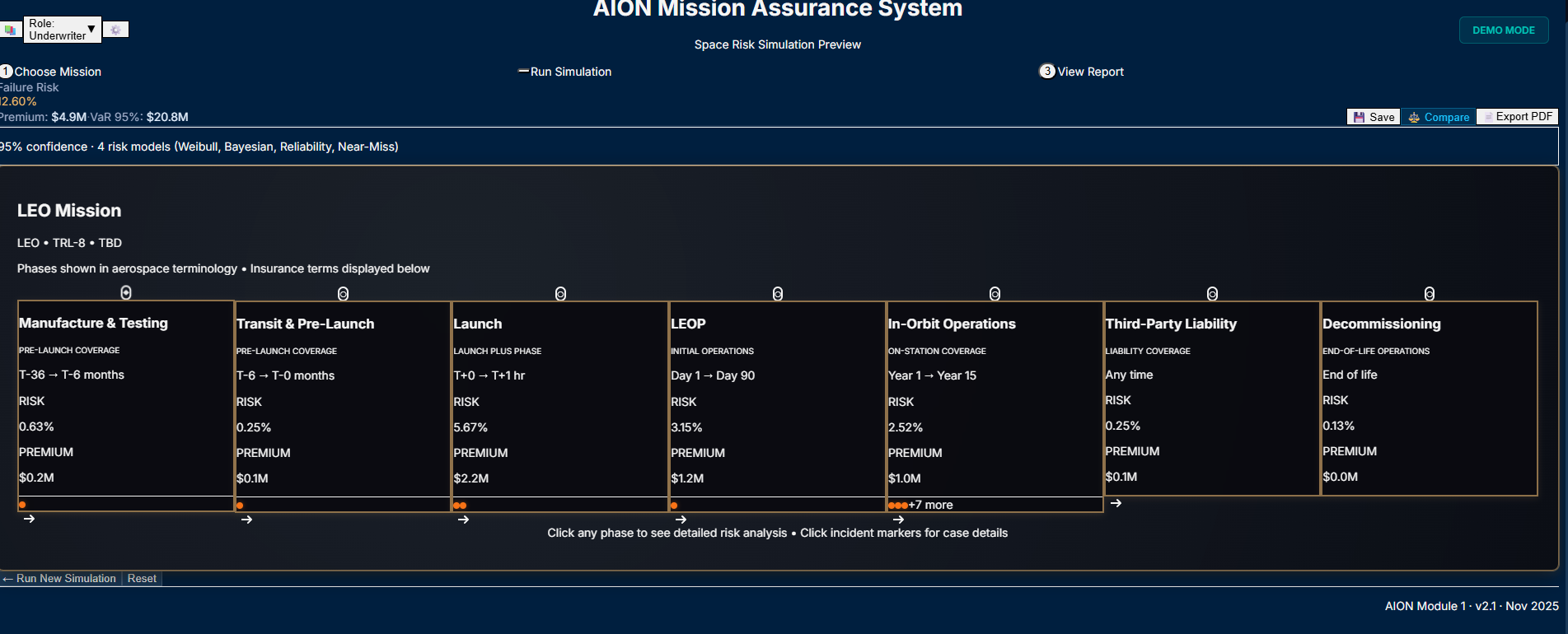
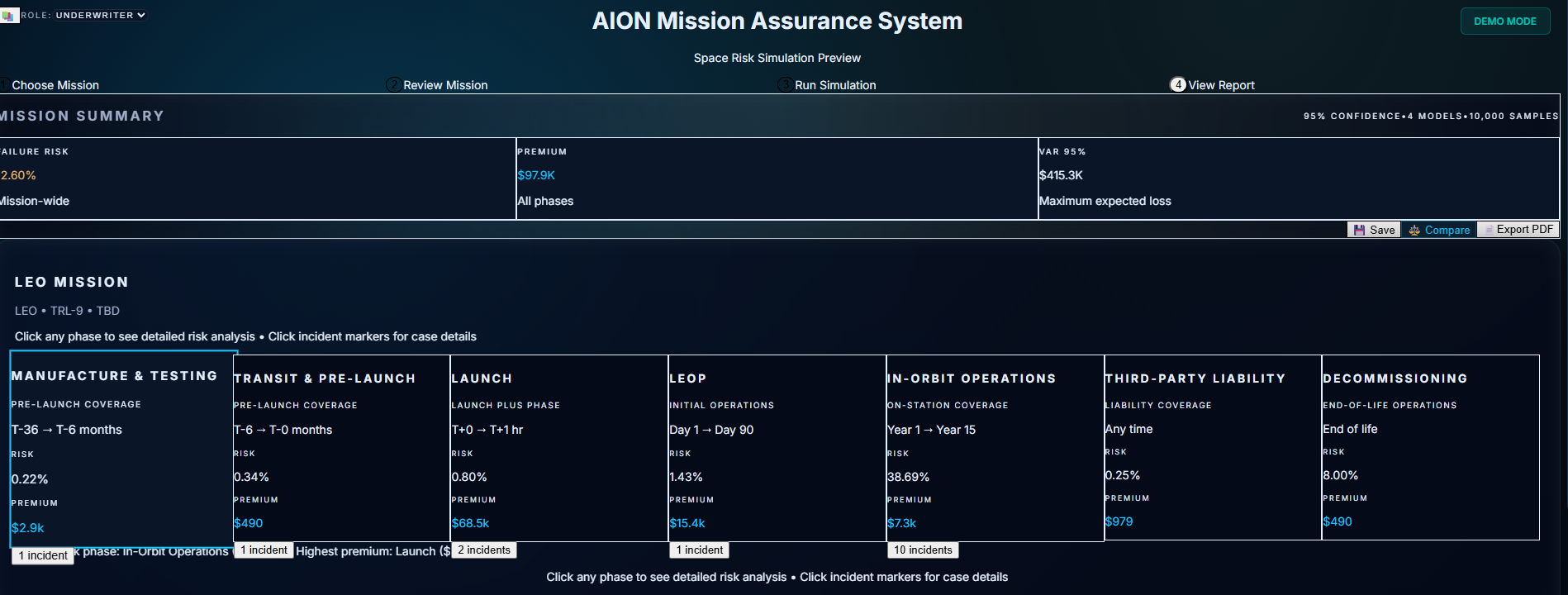
So I built the 7-Phase Mission Timeline—not just a list of dates, but a visual decision path that traces risk from Manufacture through Decommissioning. You can see historical incidents (like Intelsat 33e) mapped directly onto the timeline, showing exactly when and why certain missions failed.
What started as a functional layout became a fully restructured Underwriting Workbench:
A calmer, darker mission-view aesthetic
Clear left-to-right hierarchy
Risk band + confidence indicators
Pricing decomposition
Compliance status
Mission metadata
Environmental modifiers
A unified assumptions drawer
The design language shifted too. I moved to a Lloyd's-grade palette: navy, teal, and brass—the colours of the London insurance market. This wasn't aesthetics for its own sake. If you're building a tool for underwriters, it has to look like it belongs on their desk.
Every time I rewired something in the backend, the UI had to be reconsidered. Every time the UI exposed a gap in thinking, the backend had to be adjusted.
This back-and-forth created one of the deepest learning loops of the entire project.
Underwriter Export Packs
Phase 4 introduced exportable underwriting packs:
Mission summary
Risk assessment
Pricing components
VaR/TVaR
Compliance notes
Top risk drivers
Assumptions
Each pack is signed with a SHA-256 hash, making the result tamper-evident.
This is the first time AION produced an artefact you could send to a colleague and say, "This is the underwriting file."
Scenario Engine: Revealing Trade-Offs
Underwriters think in deltas:
"Show me the difference if TRL drops"
"What if lifetime increases?"
"What if orbit shifts?"
The scenario engine made this possible. It doesn't optimise—it reveals trade-offs.
Phase 4 Was Iteration at Scale
This phase became less about "finishing features" and more about wrestling the product into clarity:
Fixing drift between API and UI
Renaming fields for clarity
Aligning the risk and price narratives
Rewriting store logic
Adding proper null-safety
Reorganising assumptions
Refining mission types
Improving performance
Tightening validation
By the end, Module 1 finally felt integrated. Not perfect—but coherent.
Phase 5 — Hardening: Discipline as Character
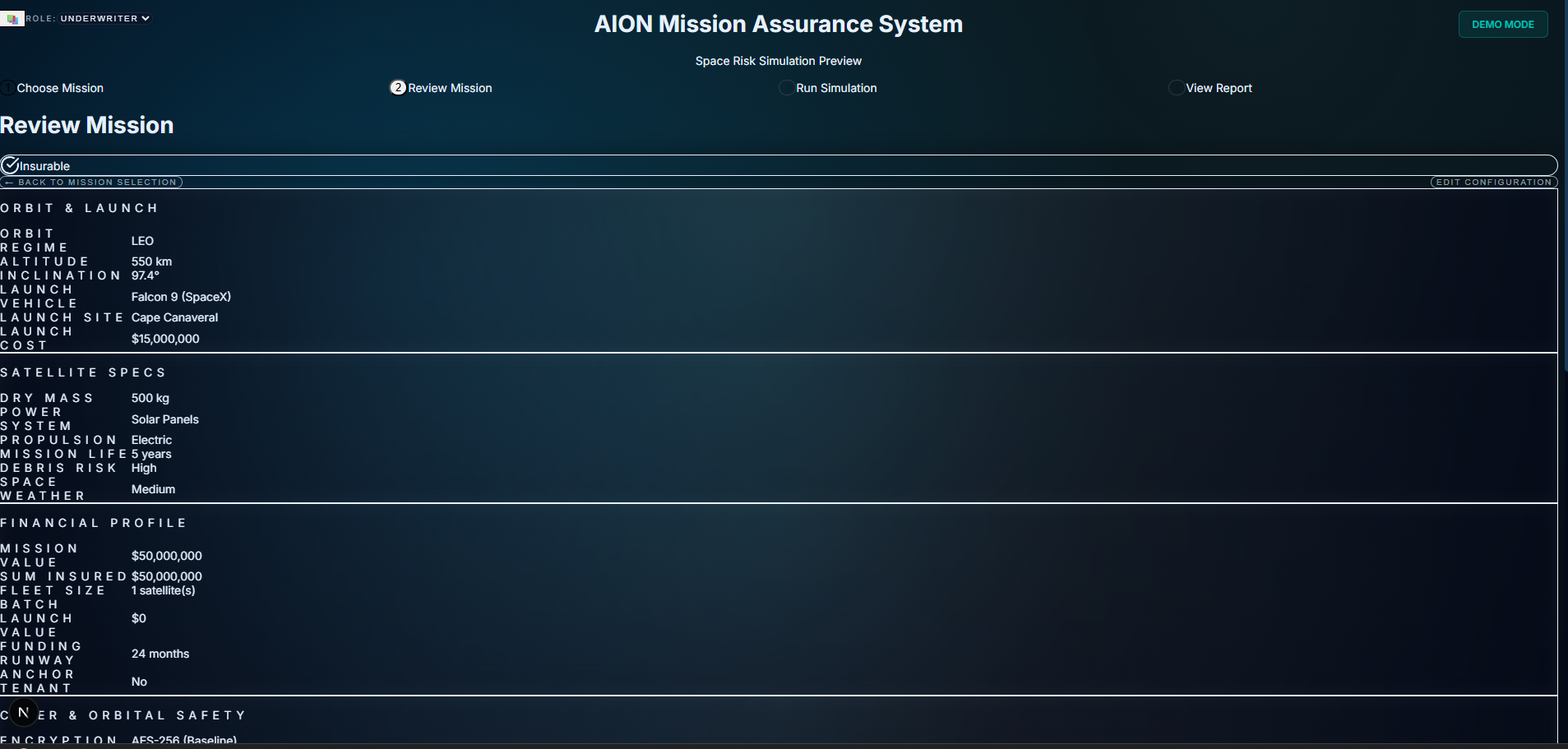
Phase 5 gave Module 1 something new: discipline.
This phase wasn't glamorous, but it changed the system's character.
The Actuarial Spine
Hardening wasn't just about writing tests. It was about replacing generic allocation logic with 1,238 lines of phase-specific actuarial code—seven distinct models, one for each mission phase:
Launch: Bernoulli distributions across 15 launch vehicles (Falcon 9, Ariane 6, Electron, etc.)
LEOP (Launch and Early Orbit Phase): Early-orbit failure curves based on historical data
In-Orbit: Weibull survival models calibrated to mission life
Payload Mission Deployment: Component-level reliability tracking
Collision Avoidance: Conjunction risk and debris environment
Quality Assurance: Manufacturing and testing rigor assessment
Decommissioning: Post-Mission Disposal (PMD) reliability tracking
This wasn't cosmetic. It meant that when AION says a GEO mission has a 3.4% annual loss probability, it's not guessing—it's running 100,000 Monte Carlo simulations across phase-specific hazard functions.
And it's fast:
Pricing latency: ~0.24 seconds
Assessment: ~0.07 seconds
Export packs (with full audit trails): ~0.27 seconds
A Full Test Suite
Module 1 now has tests for:
Each individual model
API contracts
Integration flows
Performance thresholds
Scenario comparisons
This caught issues that would otherwise hide in quiet corners—mismatched schemas, missing fields, orbit crossover bugs, incorrect priors, and more.
Observability
Phase 5 added:
run_idcorrelation_idStructured JSON logs
Metrics endpoints
API health checks
A system you can observe is a system you can fix.
Database Evolution Without Fragility
Module 1 now uses a hybrid storage strategy:
Relational fields for common queries
JSONB for risk output, pricing, explainability, scenarios, and assumptions
This prevents migration churn and keeps the engine adaptable.
Regulatory Intelligence, Not Just Risk Calculation
One thing that separates AION from a prototype is that it understands regulatory constraints, not just technical risk.
The engine now tracks:
UKSA liability bands (UK Space Agency regulatory thresholds)
ISO 24113 compliance (space debris mitigation standards)
Sanctions screening (flagging components from restricted jurisdictions)
When a mission lacks a deorbit plan or uses non-compliant encryption, AION doesn't just note it—it adjusts the pricing and flags the specific clause that's at risk.
This is what underwriters actually need: a tool that knows the rules before a quote goes out.
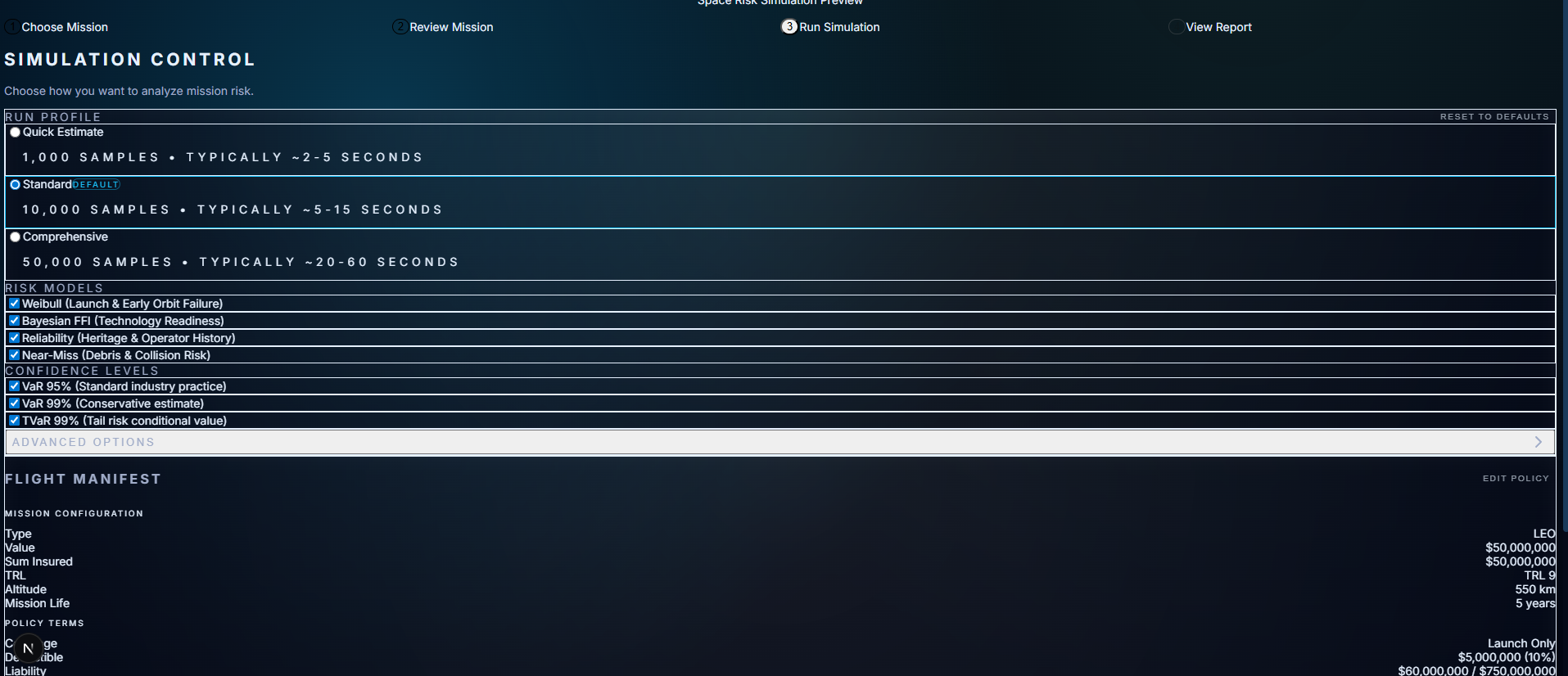
What Actually Broke (And What I Learned)
Orbit Logic Bugs
For weeks, GEO missions were being priced using LEO failure curves. The engine treated all satellites as interchangeable, which meant a geostationary comms satellite was getting the same hazard rate as a low-orbit cube sat.
I discovered this when a test GEO mission came back with a 12% annual premium—absurdly high for a stable, high-altitude orbit.
The fix required creating explicit mission classes with orbit-specific parameters.
Weibull Sampling Noise
I started with 10,000 Monte Carlo samples because "more is better," right?
Wrong.
The tail probabilities got noisier, and pricing latency spiked to 2+ seconds. Dropping to 2,000 samples cut the noise, improved speed by 80%, and cost less than 2% accuracy.
Lesson: engineering is about finding the right trade-offs, not maximising everything.
Schema Drift
Early on, I'd change a backend model output and the frontend would silently break. A field rename would cascade into missing JSON keys three layers deep.
The fix: lock API contracts with versioned schemas and enforce validation at every boundary.
Boring infrastructure work, but it's what makes iteration safe.
Missing JSON Keys
Certain nested fields triggered failures deep in the pricing logic. I added defensive defaults across the board—no more silent nulls.
Performance Bottlenecks
Unindexed columns and recomputation loops caused spikes. Profiling cleaned this up. Performance became predictable, not just "usually fast."
Each obstacle forced a deeper understanding of how underwriting logic interacts with engineering constraints.
What I Actually Built
Across Phases 3, 4, and 5:
7 phase-specific actuarial models (1,238 lines of production code)
15 launch vehicle profiles with tier classification and historical reliability data
~40 conditional risk drivers that adapt based on mission parameters
~15 actionable mitigations with quantified premium impacts
100,000-run Monte Carlo pricing engine (<0.3s response time)
Mission timeline visualisation tracing the decision path across 7 phases
Regulatory compliance engine tracking UKSA, ISO 24113, and sanctions risk
Export bundles with SHA-256 verification and PDF report generation
Full observability: correlation IDs, run tracking, model versioning
Complete UI workbench with unified AION design system
55+ bug fixes including type safety, data scoping, and performance optimisation
How I Built It
Through agent orchestration and constant research iteration.
The workflow looked like this:
Research Phase:
Deep dive in Perplexity and Gemini for actuarial standards, space insurance regulations, and technical specifications
Cross-referencing Lloyd's practices, UKSA compliance requirements, ISO 24113 standards
Planning Phase:
Compare architectural approaches across GPT, Claude, and Gemini
Iterate on sprint plans until the logic was sound across all three models
Use disagreement between models as a signal to research deeper
Specification Phase:
Build detailed spec plans in Cursor with AI assistance
Break phases into concrete sprint tasks with acceptance criteria
Define API contracts, database schemas, and UI flows before writing code
Execution Phase:
Specialised agents for different domains:
Backend agent: FastAPI routes, SQLAlchemy models, actuarial engines
Frontend agent: React components, UI state management, chart libraries
Testing agent: pytest suites, contract validation, performance benchmarks
Planning agent: Sprint retrospectives, obstacle analysis, next-phase roadmapping
Iteration Cycle:
Research → Compare Plans → Spec → Build → Test → Debug → Refactor → Ship
It wasn't linear. It wasn't tidy. But each cycle made the system more honest.
The key insight: AI agents don't replace judgment—they accelerate iteration. I still made every architectural decision, but I could test 5 approaches in the time it used to take to implement one.
Why I Built It This Way
Because the goal isn't the "best model."
The goal is a model an underwriter can trust—and trust requires more than accuracy. It requires:
Stability
The engine produces the same result for the same inputs, every time. Deterministic seeding, locked schemas, versioned APIs. No surprises.
Explainability
Every risk score traces back to specific drivers. Every premium breaks down into pure risk + catastrophe load + expense + profit. If an underwriter can't explain it to a broker, the model failed.
Calibration
LEO missions price between 5-15%. GEO missions between 1-5%. These aren't arbitrary—they're benchmarked against Lloyd's market rates and historical loss data.
Predictable outputs
Pricing stabilised at ~0.24s. Assessment at ~0.07s. No latency spikes. No edge-case failures. Performance became a feature, not a variable.
Clear assumptions
The assumptions drawer shows every prior, every weight, every modifier. You can see exactly what the engine believes about the mission.
Controlled surface area
Seven phase-specific models. Fifteen launch vehicles. Forty conditional risk drivers. The engine is complex enough to be realistic, simple enough to be maintainable.
A messy but brilliant model is useless. A clear, reliable one is valuable.
And in insurance, "valuable" means: Would you stake your professional reputation on this assessment?
That's the standard Module 1 had to meet.
What I Learned
1. Architecture is behaviour
Fixing structure fixes logic. The orchestrator pattern didn't just organise code—it made the engine extensible. When I needed to add a new compliance check or a seventh actuarial model, the architecture already had a place for it. Good systems are designed to evolve.
2. Explainability is part of the model, not a feature you bolt on
If you can't explain a calculation cleanly, something is wrong with how you've designed it. AION's risk drivers aren't generated by black-box ML—they're explicit, traceable, and grounded in actuarial logic. Transparency isn't optional in regulated industries.
3. Systems thinking beats feature building
Patterns compound. Features decay. The orchestrator pattern, mission type classes, validation layers—these structures paid dividends across every sprint. A good abstraction saves you from writing the same code fifty times. A bad one forces you to refactor constantly.
4. Product emerges through iteration, not planning
Phase 4's UI overhaul taught me that most clarity comes from using the system, not designing it up front. I rewrote the mission view three times. Each version exposed assumptions I hadn't questioned. The final design wasn't planned—it was discovered.
5. Reliability is the real milestone
Module 1 isn't finished—it's never "finished." But it's dependable. Tests pass. Performance is predictable. Outputs are reproducible. That dependability is what unlocks everything else: investor demos, underwriter pilots, Module 2 integration. Without reliability, nothing else matters.
6. AI agents accelerate iteration, but judgment still matters
Using GPT, Claude, Gemini, and Cursor in parallel let me test five architectural approaches in the time it used to take to build one. But the AI didn't make the decisions—it surfaced options. The discipline was in choosing well, not generating fast.
From Prototype to Platform
Module 1 started as a risk model. It ended as an underwriting workbench.
The transformation wasn't just about adding features—it was about building the architecture of trust. Every decision—RBAC roles, phase-specific models, compliance tracking, export verification—was designed to answer one question:
Would an underwriter trust this assessment?
By the end of Phase 5, the answer was yes.
Module 1 is now frozen at V1. It's production-ready, and capable of supporting the rest of AION's vision: a full-stack space insurance platform.

AION: Module 1 Phase 2
Phase 2 of AION’s Risk Engine was about moving from a working prototype to something an underwriter could actually trust. I rebuilt the core logic around survival curves, calibration, environmental sensitivities, and a clearer mission view to make risk reasoning easier, not flashier.
Building a Risk Engine That Underwriters Can Trust
Phase 1 of AION gave me something simple but valuable:
a loop that could take a mission, run a model, and explain its result.
Phase 2 raised the standard.
The question this time wasn’t “Can I build a risk model?” but:
“Can I build one an underwriter would trust for a first-pass view?”
That meant moving away from toy numbers and towards something closer to real insurance work: probability curves, calibrated priors, realistic failure rates, and a pricing engine that behaves like a disciplined actuarial tool, not a demo.
Opening the Model Up: Real Failure Curves
The first breakthrough in Phase 2 was replacing linear logic with proper survival analysis.
The engine now uses:
A Weibull lifetime curve
(infant mortality → stable phase → wear-out)A Bayesian update model for TRL and heritage
A reliability model tuned by orbit and launch vehicle
Hardware doesn’t fail in a straight line.
It fails according to curves, and capturing that shape immediately made the engine feel more aligned with historical space behaviour.
A positive example: fixing the inverted TRL priors.
In Phase 1, immature tech was being treated as safer — a comforting mistake.
Correcting it made the system more honest and more useful.
A Pricing Engine That Shows Its Working
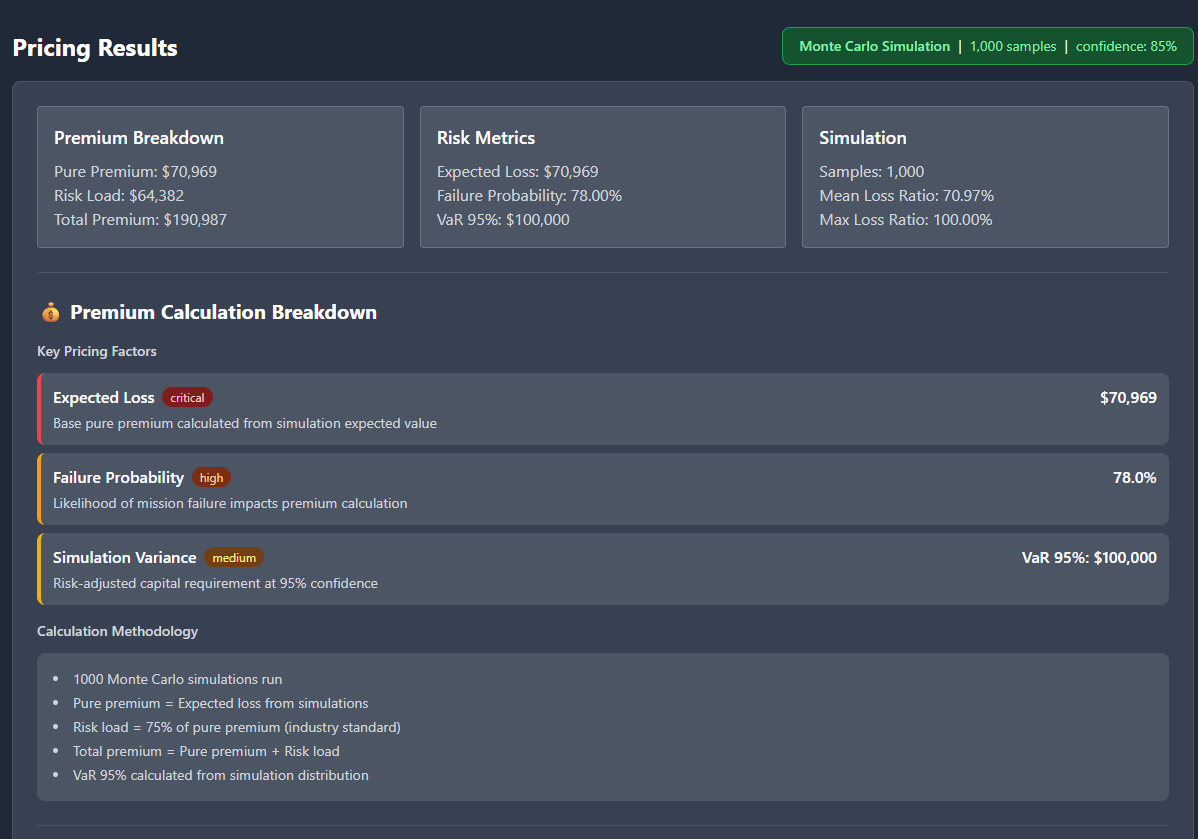
Phase 2 introduced a Monte Carlo pricing engine with:
Premium bands
VaR95 / VaR99
Tail loss behaviour
Decomposition across pure, risk, catastrophe, expense, profit
Calibration against simple industry bands
(LEO: 5–15% of SI, GEO: 1–5%)
The engine now runs 50,000 quantile samples (seeded for reproducibility) and treats price as a consequence of the probability curve, not a lookup table.
The most important addition was the explicit premium decomposition:
Here is what drove the risk.
Here is the impact of each adjustment.
Here is why the premium sits here.
It forced me to think like an underwriter rather than a developer.
Calibrated Priors: Bringing Discipline to the Numbers
Phase 2 introduced a more disciplined calibration layer:
Blend weighting: 0.09·model + 0.91·prior
Orbit caps: LEO 0.12, GEO 0.06
Realistic failure rates: Falcon 9 ≈ 97.7% success
Severity modelling:
20% total loss
80% partial loss (Beta distribution, 10–40% SI)
These numbers aren’t perfect, but they stop the model from being overconfident just because the Monte Carlo chart looks pretty.
Calibration isn’t a cosmetic step — it’s a form of intellectual honesty.
Adding Environmental Sensitivities
Space isn’t a static environment, so the model shouldn’t be either.
Phase 2 added:
Conjunction density → increases probability
Solar activity (solar_high) → increases severity and thickens the tail
These modifiers aren’t meant to be hyper-accurate.
They’re meant to teach the right behaviour:
Risk is dynamic.
Compliance: The First Signs of Real-World Constraints
I added a light compliance layer that addresses the following areas:
licensing
deorbit planning
anomaly reporting
grey-zone mapping (
fallbacks.yaml)
If a mission is unlicensed, the model applies a simple, transparent rule:
+10% premium, via a feature flag.
It’s the first time AION began to link technical risk with regulatory exposure — something Phase 1 ignored entirely.
A Mission View That Reduces Cognitive Load
Phase 2 reorganised the UI into a single mission workbench:
Mission profile
Risk band + confidence
Pricing band + decomposition
Compliance flags
Environmental modifiers
An assumptions drawer showing the engine’s reasoning
Adjustment chips explaining signal impacts
It’s not polished.
But it has a calm structure you can actually think inside — which is more important at this stage than visual flair.
Reducing cognitive load was the whole point.
What This Phase Taught Me
Modelling is a negotiation with reality.
Every fix — inverted priors, overflow issues, curve tuning — revealed where intuition diverged from the world.
Underwriters don’t want a number; they want the reasoning trace.
The more transparent the model became, the more confident I became in its behaviour.
Calibration is honesty encoded as math.
Small parameters grounded the system more than any big feature.
Tools shape thinking.
Designing a single mission view changed the way I built the model itself.
What Phase 2 Sets Up
Phase 2 didn’t finish the engine.
It clarified the foundation.
It taught me to build something that:
behaves predictably
explains itself rigorously
stays within calibrated bounds
is structured for future extension
can sit in front of a professional without apology
Phase 3 will focus on refining the narrative layer:
clearer assumptions, more consistent reasoning, and a tighter link between risk, environment, compliance, and price.
But for the first time, the engine feels usable.
Not finished.
Not perfect.
But grounded enough to build on with confidence.